Ich beschäftige mich seit geraumer Zeit damit in meinem Keller aufzuräumen und auszumisten. Die Sachen die ich aufhebe, habe ich bisher in einer Excel Datei aufgelistet, damit ich sie leichter wiederfinde. Es war ein einfacher Ansatz um zu starten, ist allerdings nicht sehr Komfortabel. Weder beim Gruppieren, noch beim Eintragen, und schon gar nicht beim Suchen.
Nach dem Motto: „Excel is NOT a Database“ habe ich mein System nun umgestellt.
Aber von vorne. Für meine Slotracing Website habe ich die erste Version meines CMS (Content Management System) programmiert. Mit meinem Energiedashboard kam eine Domainübergreifende Benutzer und Rechte Verwaltung dazu, und mit meiner digitalen Einkaufsliste kam die AJAX Datenbank Suchfunktion dazu. Des weiteren eine Erkennung des Endgerätes und ein Modul welches die Website als PWA (Progressive Web App) ausgibt damit es sich auf einem Mobile-Device wie eine native App verhält.
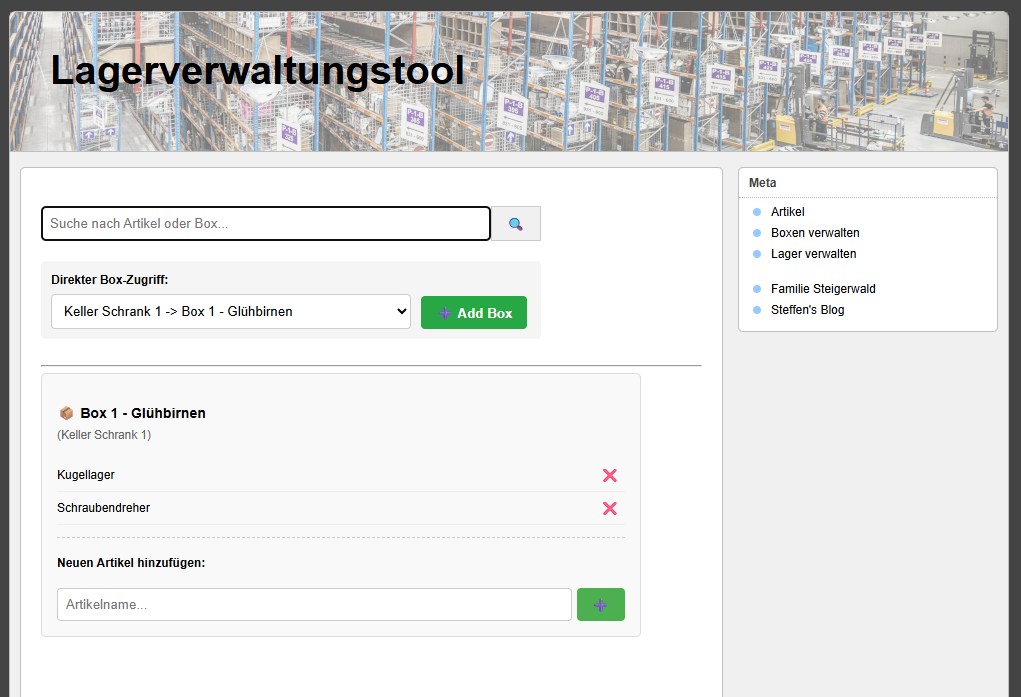
Auf dieser Basis habe ich gestern Abend in zwei Stunden mein Lagerverwaltungstool erstellt, was meinen Excel Aufschrieb ersetzt.
Man kann beliebige Lagerorte anlegen und man kann verschiedenste Boxen anlegen welche man einem Lagerort zuweisen kann. Auf der Hauptseite kann man entweder nach einem Schlagwort suchen wobei man während der Eingabe schon Vorschläge bekommt, oder über den Suchbutton eine Liste anzeigen lassen. Alternativ kann man auch über das Dropdown direkt über die Box einsteigen. Oder man beginnt mit einer neuen Box. Auf jeden Fall wird dann der Inhalt der Box angezeigt welchen man Hinzufügen oder Entfernen kann.
Bevor die folgenden Zeilen jemand in den falschen Hals bekommt, möchte ich ausdrücklich darauf hinweisen das ich mir das Gerät bewusst und im vollem Besitz meiner Geistigen Kräfte gekauft habe. Auch möchte ich keinesfalls jemandem einen Vorwurf machen, da ich die von mir benötigten Funktionen vor dem Kauf abgewogen habe. Zugegebener Weise nicht in jeglicher Hinsicht korrekt. Das hat mich in den letzten Wochen stark frustriert was sich in diesem Artikel niederschlägt. Wer mich kennt weiß allerdings dass das letzte was ich tue Aufgeben ist.
Hier hatte ich bereits erwähnt das mir Zendure empfohlen wurde und wie ich geplant hatte diese in meine HomeAutomation einzubinden. Zunächst aber erst mal ein paar Infos um die Zendure Landschaft zu verstehen:
Zendure ist der Hersteller
Zendure SolarFlow ist die Produktkategorie
SolarFlow 1600 AC+ Ist in meinem Fall das Produkt
Hub nennt Zendure seine Steuerungskomponente im Gerät
Zendure Cloud nennt Zendure ihren Hauseigenen MQTT Broker
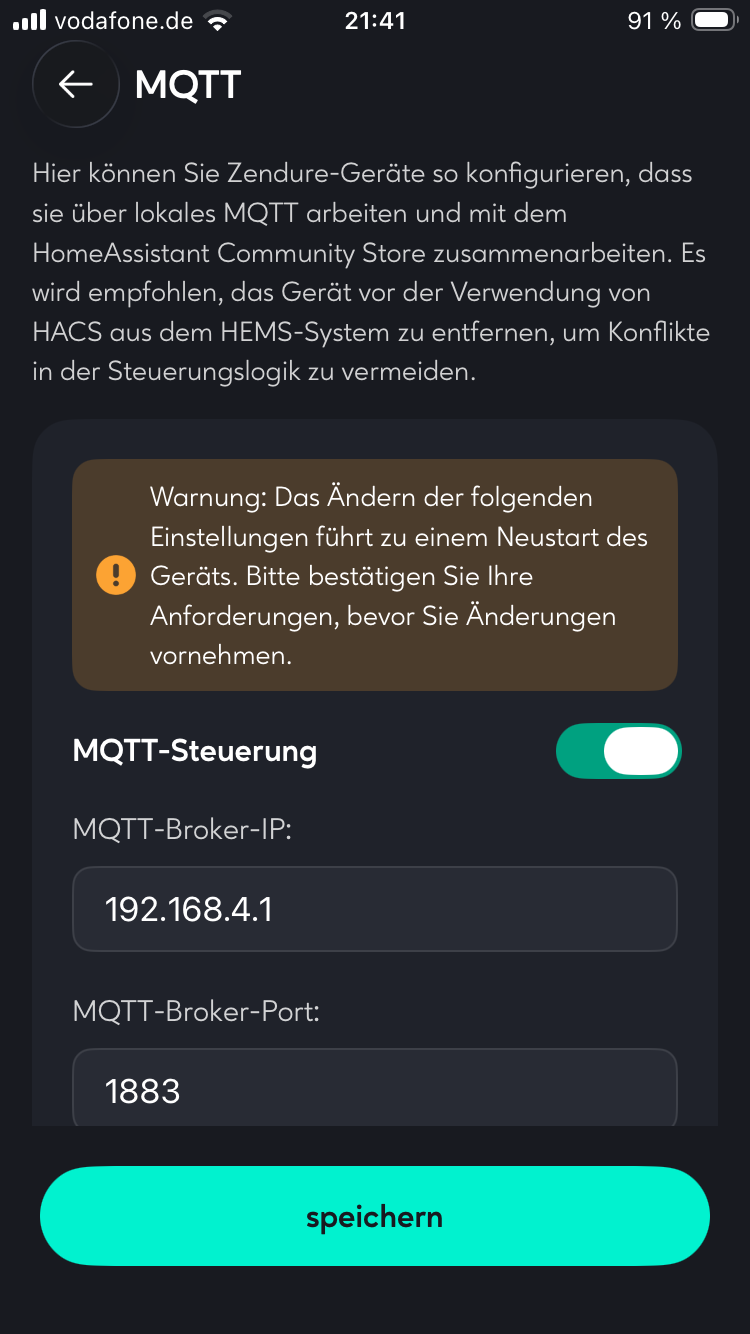
Nach anfänglicher Euphorie beim Testen meines Proxys mit dem Laptop kamen mir dann doch Bedenken weil ich immer wildere Dinge über die Absicherung des Zendure SolarFlow Hubs und dessen MQTT-Clients gelesen habe. Das war glücklicherweise Grundlos. Als die Kiste kam, habe ich diese über die App in Betrieb genommen und mit dem WLAN des S3-Proxies verbunden. Katsching, sofort hatte ich die SolarFlow auf dem Broker. Super Start dachte ich noch. Pustekuchen. Beim Rumspielen mit den Sollwerten musste ich feststellen, das die Istwerte sich in der App innerhalb 4-10 Sekunden ändern, auf dem MQTT allerdings 16 – 60 Sekunden benötigen. Eine Regeltechnische Katastrophe. Zu diesem Zeitpunkt dachte ich das es eventuell am ESP32 liegt. Also musste eine Alternative her. In der neuesten Firmware kann man nun Praktischerweise einen eigenen MQTT Broker einstellen.
Prima, man öffnet sich den Kunden. Und wieder war mein Gedanke völlig abwegig. Dieser funktioniert nämlich nur dann wenn der intern Voreingestellte mit der Cloud verbunden ist. Keine Verbindung zur Cloud, keine Nachrichten auf dem privaten Brocker. Ok, zum Testen die Kiste ins Internet gelassen, und siehe da …
Enttäuschend. Die selbe Latenz ohne eventuell limitierende Bridge zwischendrin. Daran lag es also nicht. Allerdings kommt auf diesem Weg noch Unmengen an Datenmüll hinzu. Zunächst die Daten des Hubs, der Batterien, und der Off-Grid Steckdose, was den selben Daten im Cloud MQTT entspricht. Das wäre OK, aber zusätzlich Strukturen für Home-Assistant, IO-Broker und was weiß ich noch alles. Und nichts davon konfigurierbar. So geht’s jedenfalls auch nicht.
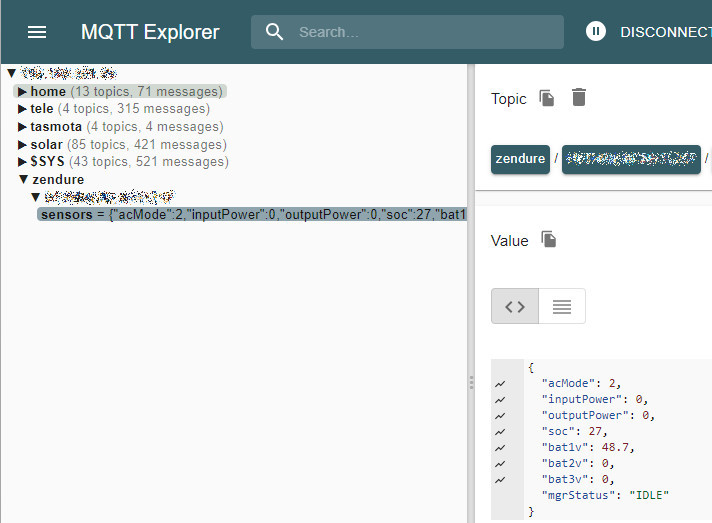
Nach mühseligen Tagen auf der Suche nach Lösungen bei der mir Gemini und ChatGPT keinen Millimeter geholfen hat, habe ich in einem Forum in dem es um etwas ganz anderes ging das Schlagwort „ZenSDK“ entdeckt. Das ganze Meisterwerk ist, wie soll es denn anders sein, nicht öffentlich Dokumentiert. An dieser Stelle konnte mir Gemini dann weiterhelfen. Denn die GET und POST Anfragen enthalten die selbe JSON Struktur wie bei MQTT. Das ist zwar auch nicht öffentlich Dokumentiert, aber hier hat Reinhard Brandstätter schon reichlich Vorarbeit geleistet. Auf GitHub zu finden unter reinhard-brandstaedter.
In Powershell kurz GET und POST getestet
PowerShell:
Invoke-WebRequest -Method Get -Uri "http://192.168.4.2/properties/report"
Und siehe da, die Istwert Änderung wird sofort angezeigt sobald diese in der App ersichtlich ist wenn nicht sogar schneller. Die SolarFlow also wieder vom Internet getrennt, aber was ist das? Keine Cloud heißt kein API (Application Programming Interface). An dieser Stelle greife ich etwas vor, denn der Hub verbindet sich nicht nur mit dem Zendure MQTT Broker sondern auch mit deren NTP-Server. Und ohne die Zeit schaltet die SolarFlow die Ausgänge nicht frei. Die haben doch nicht mehr alle Latten am Zaun.
Es muss die Frage gestattet sein: Wie steure ich meine „Off-Grid Steckdose“ wenn der Strom weg ist und der Router dadurch keine Internetverbindung mehr herstellen kann. Ach ja richtig, ich kann sie ja vorher schon einschalten wenn ich weiß das gleich ein Stromausfall kommt. Auf die 20 Watt Inverter Leistung im Leerlauf ist ja geschissen.
Also die Solarflow wieder mit dem S3-Proxy verbunden und damit mit meinem Broker. Da geht es dann wieder. Aber nun hatte ich den ganzen MQTT-Müll wieder auf meinem Broker. Der Plan: Erstens den Proxy umbauen, und dann den Zendure Controller bauen.
Die neue Bridge (Proxy)
Zunächst einmal sei gesagt das Zendure anders als vielmals erwähnt oder behauptet, die Pakete nicht über Port 8883, also „MQTT over TLS“ verschickt, sondern unverschlüsselt über Port 1883 was noch ein Grund mehr für mich ist, die SolarFlow nicht ins Internet zu lassen. Dazu kommt, dass Zendure die Pakete mit QoS0 (Quality of Service Level 0) sendet, also „fire and forget“ was in dem Fall gut für mich ist. Denn so muss der Client ja gar nicht wirklich mit einem Brocker verbunden sein. Er muss nur denken das er es ist. Das Ganze nennt sich Mocking. Man erstellt einen TCP Socket auf Port 1883. Der MQTT Client verbindet sich dorthin, ist verbunden und ballert seine Pakete ins Nirvana.
So habe ich dann meine Bridge zum Testen umgebaut. Das weiterleiten von Port 1883 und 8883 habe ich entfernt. Dafür kam das oben erwähnte TCP Socket in den Code. Wer mal damit spielen will:
Python:
import socket
# TCP Server auf Port 1883 starten
server = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
server.bind(('0.0.0.0', 1883))
server.listen(1)
print("Dummy-Broker wartet auf Clients...")
while True:
client_socket, addr = server.accept()
print(f"Verbindung von {addr}")
# 1. CONNECT Paket vom Client empfangen (wird hier ignoriert)
connect_packet = client_socket.recv(1024)
# 2. Das magische CONNACK zurücksenden
client_socket.send(b'\x20\x02\x00\x00')
print("CONNACK gesendet. Client ist drin!")
# 3. Jetzt kommen die QoS 0 Daten reingeflattert
while True:
data = client_socket.recv(1024)
if not data:
break
print(f"Rohdaten empfangen: {data}")
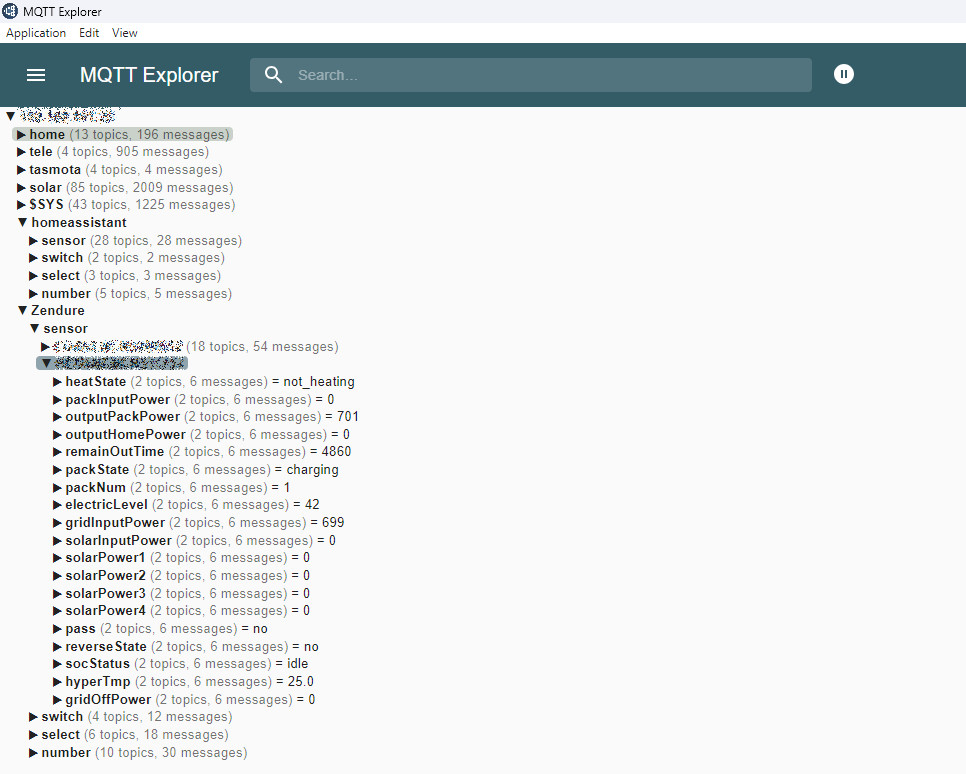
Da die DNS Anfragen an mqtt-eu.zen-iot.de eh schon an die 192.168.4.1 umgeleitet waren, verbindet sich der Hub nun mit dem digitalen Bermudadreieck. Nun Funktioniert technisch alles so wie ich es will. Ich kann die SolarFlow mit wenig Latenz ansprechen, sie ist nicht mit dem Internet verbunden und müllt mir nicht meinen MQTT Brocker voll.
Der Controller (Knoten im Hirn)
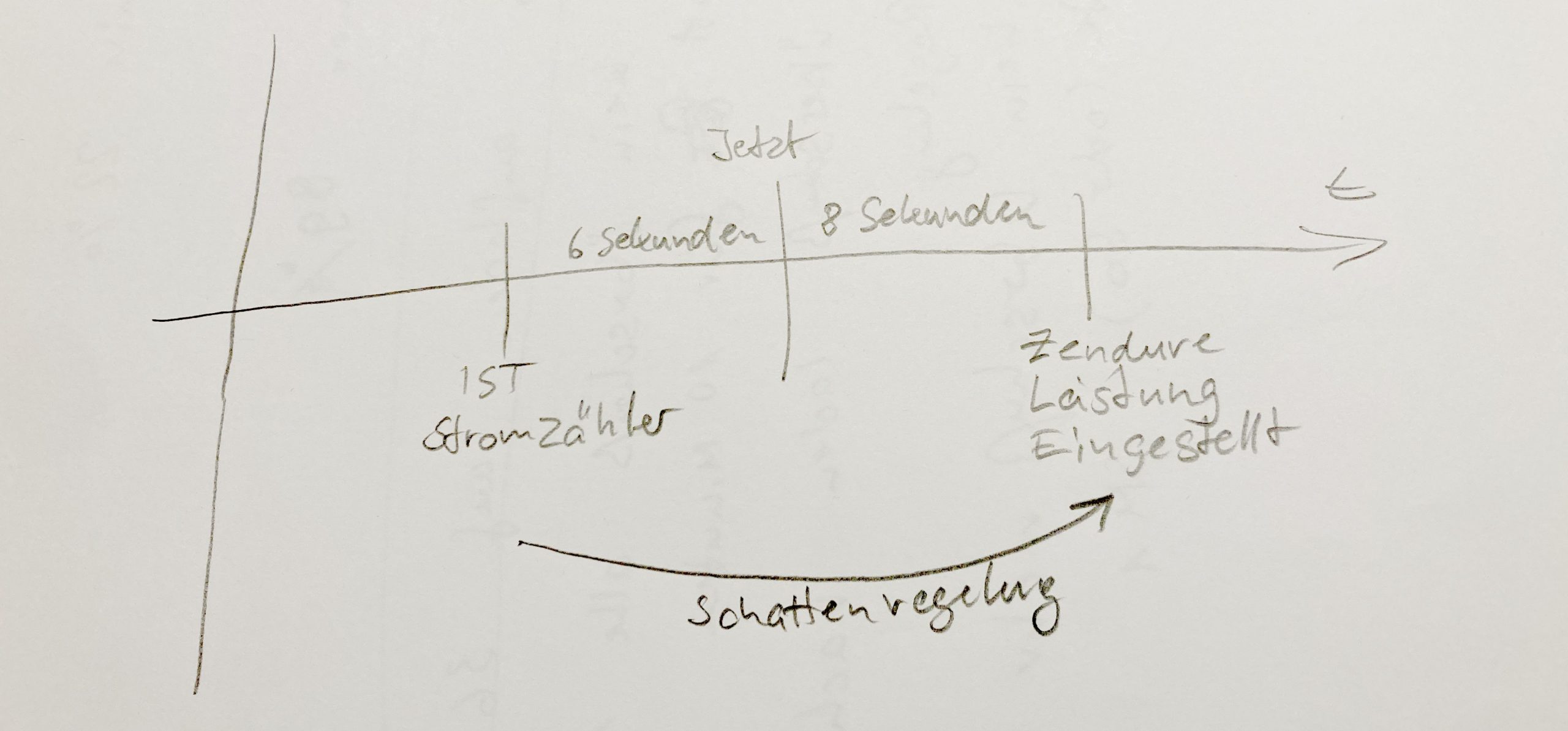
Das schlimmste wäre geschafft, dachte ich da noch. Welch wunderbarer Traum. Ich bekomme meine Stromzählerwerte über einen Hitchi Sensor der mir diese über Tasmota an den Broker schickt. Wenn ich nun eine Glühbirne einschalte, dauert es ca 3-6 Sekunden bis die Änderung am Stromzähler abzulesen ist. Für meine Stromkosten ist das nicht relevant aber es ist eine Latenz die bei der Regelung berücksichtigt werden muss. Dazu kommen konstante 3 Sekunden, bis die Änderung im Broker angekommen ist. Zum Zeitpunkt meiner Stellwertermittlung liegt das in der Vergangenheit. Nun setze ich den Stellwert und es dauert je nach Regelabweichung und Situation 1-16 Sekunden bis der Zielwert in der SolarFlow erreicht ist. Ist die SolarFlow in Regelung kann man von maximal 8 Sekunden ausgehen. Sowas steuert man nicht mehr über einem PID-Regler.
Also hab ich die KI befragt und als Antwort kam: Du brauchst einen Smith-Prädiktor. Das kam mir irgendwie bekannt vor, allerdings hatte ich vermutlich das letzte mal in der Ausbildung davon gehört. Aber warum einfach wenn’s auch kompliziert geht. Immerhin ist es in diesem Fall dann gleich ein Smith-Prädiktor mit zwei zeitlich variablen Messgrößen. Uiuiuiuiui, ich weiß gar nicht wie ich das beschreiben soll. In den Worten von Gemini:
Ein erweiterter Smith-Prädiktor für zwei zeitlich variable Messgrößen nutzt ein mathematisches Prozessmodell, um die jeweiligen, sich dynamisch verändernden Totzeiten beider Eingangsgrößen parallel zu simulieren und rechnerisch zu kompensieren. Dadurch kann der Regler auf Basis von verzögerungsfreien Vorhersagen agieren, noch bevor die echten, variablen Effekte an den Messstellen messbar sind. Auftretende Modellabweichungen werden über eine kontinuierliche Differenzbildung mit den realen Zählerwerten korrigiert, was den Regelkreis selbst bei schwankenden Latenzen stabil hält.
Gecheckt? Ok, dann kann’s weiter gehen. An diesem Punkt angekommen, wundert es mich nicht das der Akkudoktor (Andreas Schmitz) bei seinen DIY Regelungen immer nur 10 Watt hoch oder runter regelt. Das will ich so nicht haben. Man stelle sich vor: 600 Watt PV-Überschuss. Man lädt den Akku mit 600 Watt. Es kommt ne Wolke und es dauert in 10er Schritten multipliziert mit der Latenz erst mal 1½ Minuten bis der Sollwert auf 0 ist. Die Wolke ist weg und es dauert wieder 1½ Minuten bis die Regelung wieder bei 600 Watt ist.
Nun ist es in letzter Zeit sehr bequem geworden zu Programmieren. Man schreib die passenden Prompts zusammen, übergibt es dem LLM, prüft den erhaltenen Code und ändert die ein oder andere Stelle. So habe ich es auch diesmal gemacht. Das ging leider in die Hose. Nicht nur einmal. Die Regelung hat nicht das gemacht was sie sollte. Ich konnte dem LLM einfach nicht beibringen, das der Leistungswert des Stromzählers nicht der Absolutwert im Gesamtsystem ist. Hatte ich Gemini davon überzeugt die richtige Sollwertberechnung aus Beispielsweise Einspeiseleistung und Zählerwert zu berechnen, hat er es bei den Regelbedingungen wieder rausgeworfen. Mehrere Threads führten zu Todesspiralen. Die KI hat sich jedes mal aufs neue verrannt.
Also musste ich es wie früher selbst Programmieren was nunja doch recht langwierig ist, wenn man’s inzwischen anders kennt. Angefangen mit dem Interface! Danach eine „State Machine“ und am Schluss die Sollwertberechnungen je Zustand. Es war total Irre. Wann ist der Messwert so und wann so. Rein und raus, plus ist minus und eins ist NULL. Da weiß man nicht mehr ob man Männlein oder Weiblein ist. Aber das ist nicht das schlimmste. Man denkt es funktioniert alles, und dann kommt die Zendure Logik ins Spiel. Man könnte ja Meinen, wenn man einen Input Wert setzt, der die Leistung angibt mit der der Akku geladen wird, und einen Output Wert, der angibt wieviel Leistung eingespeist werden soll, das sich das gegenseitig verriegelt, zumal man mit dem Wert acMode:1 das Laden aktiviert und mit acMode:2 das Einspeisen. Dann müsste die Regelung funktionieren! Aber NEIN. Der Stromzähler springt wie ein Hoppelhase durch die Gegend und man fragt sich warum? Warum nur? Wo ist der Fehler? Doch man findet keinen Fehler! Und irgendwann schaut man in die App und sieht: Die Kiste lädt den Akku und speist gleichzeitig ins Haus ein, über das gleiche Kabel. Was ein Blödsinn. Dann findet man raus, das man erst Output:0 und Input:0 schicken muss, bevor man die Richtung umkehrt. Wenn man Output:0 und Input:300 hinschickt und gleichzeitig acMode:1 weil man mit 300 Watt laden will, überschreibt der Hub den Output nicht mit 0. Dabei funktioniert das perfekt in die andere Richtung. Und das ist auch noch Absicht. Ich muss mich verbessern. Denen fehlen keine Latten, die haben gar keine Latten mehr am Zaun.
Wie dem auch sei. Nach etlichen Korrekturen funktioniert der Controller inzwischen astrein. Besser sogar als ich erwartet habe. Er regelt fantastisch aus bis aufs letzte Watt. Und das innerhalb von Sekunden. Nach nun 3 Tagen hat er bis aufs BMS Kalibrieren alle Zustände durch, und die Tests bestanden.
Beim bauen der Firmware habe ich nun auch eine Funktion zum Updaten der Firmware „over the air“ eingebaut, auch mit Blick auf folgende Projekte. Nun kann ich beim Kompilieren unter folgenden Punkten wählen:
env:usb – Erstes beschicken oder für den Notfall über USB im Testbetrieb
env_test – Update OTA im Testbetrieb
env_live – Update OTA im Livebetrieb
In der Programmierumgebung muss ich einmalig einen „devicename“ angeben. Dieser wird als OTA-Hostname des ESP32 hinterlegt. Im Programmcode kann ich dann bei allen Funktionen sagen, was im Testbetrieb passieren soll, und was im Livebetrieb. So kann beispielsweise die Poolsteuerung laufen, während ich eine neue Version ohne die Sensoren teste. Sobald mir das Ergebnis passt schicke ich die neue Firmware als Live-Version auf den ESP32 im Pool wo er mit den Sensoren läuft, ohne das ich den Programmcode anpassen muss.
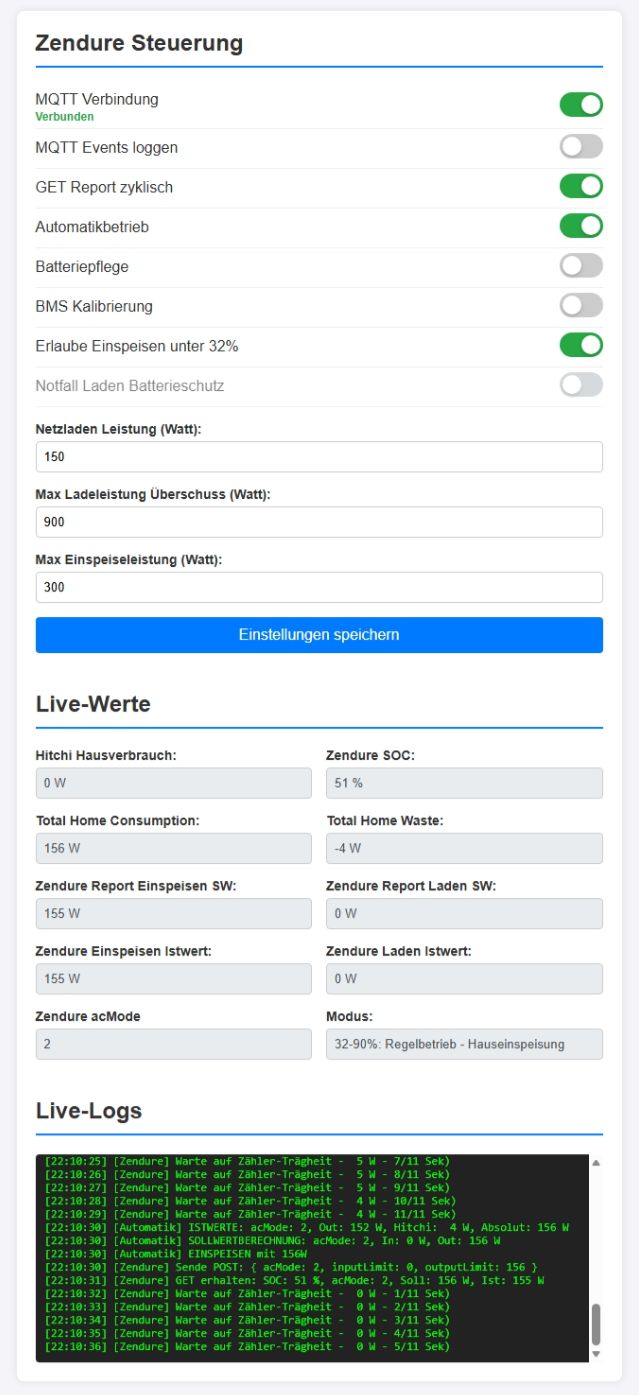
Achja, eine Ausgabe der wichtigen Zendure SolarFlow Werte landen inzwischen nahezu in Echtzeit auch auf meinem Brocker.
Mir fällt ein Riesen Stein vom Herzen, das dieses Kapitel endlich erfolgreich geschlossen werden kann. Nachdem alles läuft kann ich mir jetzt meine zweite Batterie zur Erweiterung bestellen.
Fazit
Lasst euch von Versprechen über „sich dem Markt öffnende Systeme“ nicht in die irre Führen. Auch wenn Hersteller mit Flexibilität und Zugänglichkeit werben, landen die Daten am Ende doch in der Cloud. Gekapselte Systemlandschaften wie die von Zendure sind für die Erweiterung bestehender Anlagen ungeeignet. Wer verhindern will, dass seine Anlagendaten im Internet landen, sollte einen Bogen um diese geschlossenen Ökosysteme machen.
Nachtrag 22.06.2026
Die Hardware von Zendure ist echt gut, da gibt es nichts zu Meckern. Meine zweiter Batterie kam, ich hab das System zusammengesteckt, und ab gings.
Den Softwareentwicklern hingegen hätte ich schon längst den Stöpsel gezogen. Vor ein paar Tagen sehe das mein SoC bei 100% ist, obwohl ich nach meiner Logik bei 90% aufhöre zu laden. Damit ich aber zum Kalibrieren des BMS einmal im Monat bis 100% laden will/muss, muss mein eingestellter Max-Limit Wert bei 100% sein. Jetzt ist mir gestern wieder aufgefallen das ich bei 94% noch lade. Meine App läuft im ERROR Modus, springt aus dem ERROR raus weil GET erfolgreich funktioniert, sendet POST mit {acMode: 1, InputPower:0, OutputPower:0} erfolgreich und springt beim Vergleichen der Soll und Istwerte wieder ins ERROR weil die Werte nicht zusammenpassen. Jetzt habe ich festgestellt, das Zendure kein acMode:1 also Laden mit 0 Watt kennt. In dem Fall denkt sich die Firmware, keinen Bock, ich schreibe einfach den Wert 0 nicht ins Register und lade einfach weiter.
Gestern wurde ein Projekt fertig, an dem ich schon länger gebastelt habe. Es war ein Projekt das mir sehr am Herzen liegt, wobei die Dringlichkeit immer mal wieder zu und abgenommen hat. Es handelt sich um eine Einkaufsliste die mehrere Personen nutzen können. „Ach, da gibt es ja hunderte im App-Store!“ könnte man mir sagen. Ja das stimmt, ist meine nüchterne Antwort, aber keine die so auf meine Wünsche und Bedürfnisse zugeschnitten ist.
Ich habe mir einige davon angeschaut, aber am Schluss bin ich dann mit meinem Schatz doch wieder in der WhatsApp Einkaufsgruppe gelandet.
Was sind denn nun meine Anforderungen?
Schnelles und einfaches hinzufügen von Produkten.
Wenig Traffic, kein Polling
trotzdem mehrere User auf einer Liste, also gemeinsames Einkaufen möglich
Aber jetzt kommt das wichtigste. Die Produkte sollen in der Reihenhole in der Liste stehen, wie sie auch im Supermarkt platziert sind. Und zwar für die Supermärkte in denen ich am liebsten einkaufe. Achja, und eine Rezeptdatenbank mit Produktverwaltung ist kurzfristig auch noch dazugekommen.
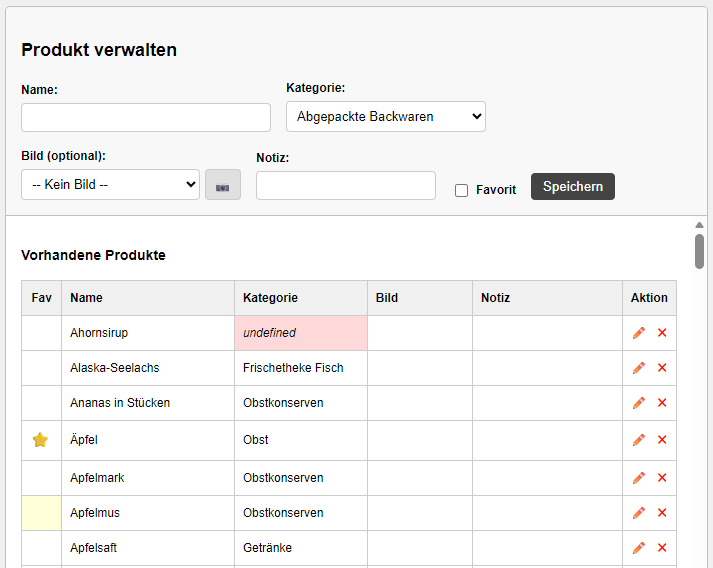
Aber schauen wir’s doch einfach an. Die Einkaufsliste läuft auf meiner Webpräsenz. Es wird unterschieden ob der Client ein Desktop- oder Mobil-Browser ist. Die Konfiguration ist am einfachsten über den Desktop zu erledigen. Produkte kann man entweder in der Produktverwaltung anlegen, über eine API, oder indem man sie einfach der Einkaufsliste hinzufügt. Hier entsteht zunächst ein Schattenartikel, dem man einen Namen und zusätzliche Informationen sowie ein Foto mitgeben kann. Nicht spezifizierte Produkte erscheinen immer am Ende der Einkaufsliste, sind aber für die Auswahl beim nächsten hinzufügen Auswählbar.
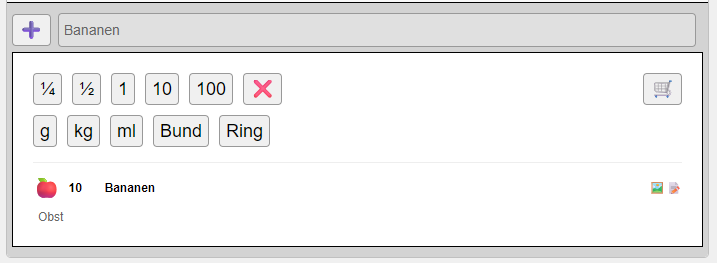
Bei vorhandenen Produkten bekommt man beim Tippen bereits Vorschläge gemacht und kann diese übernehmen.
Danach optional noch die gewünschte Anzahl und welche Maßeinheit.
Schon ist der Artikel in der Einkaufsliste. Gleiche Produkte mit gleicher Maßeinheit werden automatisch aufsummiert. Optionale Informationen und Fotos werden durch die Icons dargestellt und können angeklickt werde, wodurch sie in einem Overlay angezeigt werden. Ganz oben kann man seinen Wunschsupermarkt einstellen, wodurch sich die Sortierung der Produkte entsprechend anpasst. In der Produktverwaltung kann man Produkte direkt anlegen.
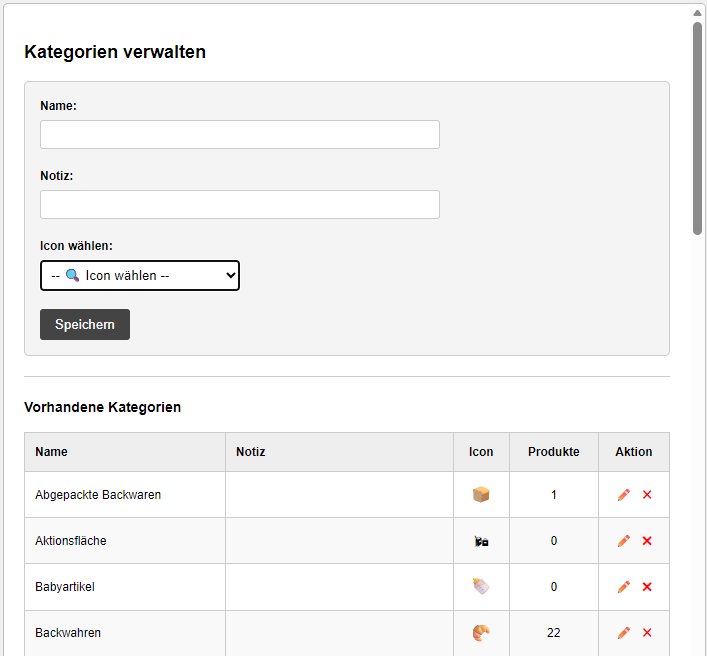
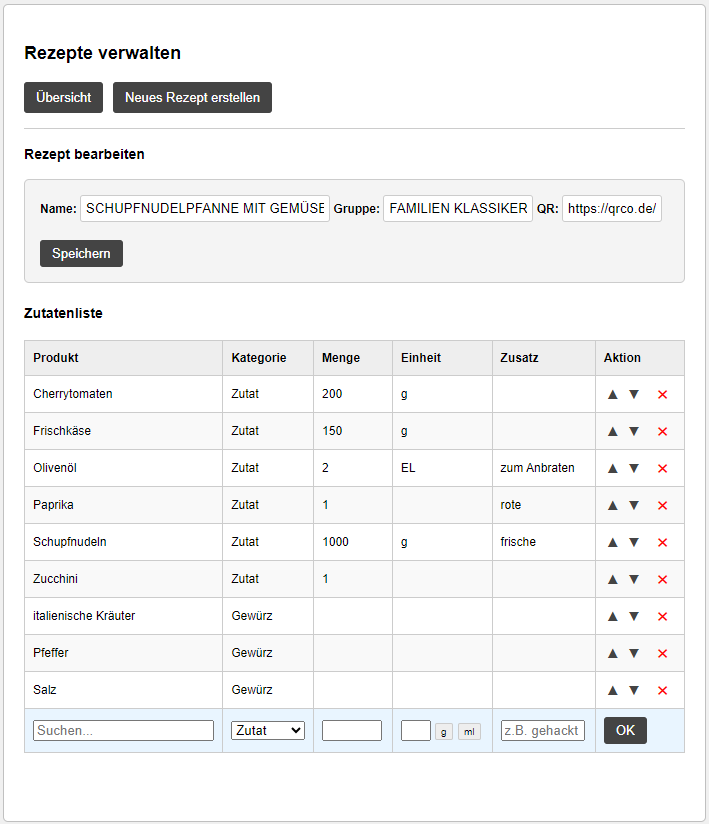
Beim Schreiben erhält man ebenfalls Hinweise, welches Produkt bereits vorhanden ist. Bei der Kategorie wird es nun interessant. Denn auf der Kategorie basiert die Navigation im Supermarkt. In der Produktverwaltung angelegten Produkten muss man gleich die Kategorie einstellen. Auch hier kann man Fotos knipsen, Bilder einfügen, und Notizen machen. Beliebte Produkte kann man als Favorit markieren. Hierfür gibt es auch eine Toggle Funktion in der Favoritenspalte. Fährt man mit der Maus drüber wird das Feld hervorgehoben und durch klicken kann man den Favoriten setzen oder entfernen. Anderweitig hinzugefügte Produkte haben die Kategorie „undefined“. Diese werden rot hervorgehoben und müssen von Zeit zu Zeit einer Kategorie zugewiesen werden. Die Kategorien müssen einmalig angelegt werden.
Hierzu habe ich in der Supermarkt-Scene recherchiert. Wie Supermärkte organisiert werden, welche Produkte wie platziert werden, und welche Produktgruppen daraus abgeleitet werden können. Diese habe ich angelegt und mit einem für mich passenden Emoji versehen.
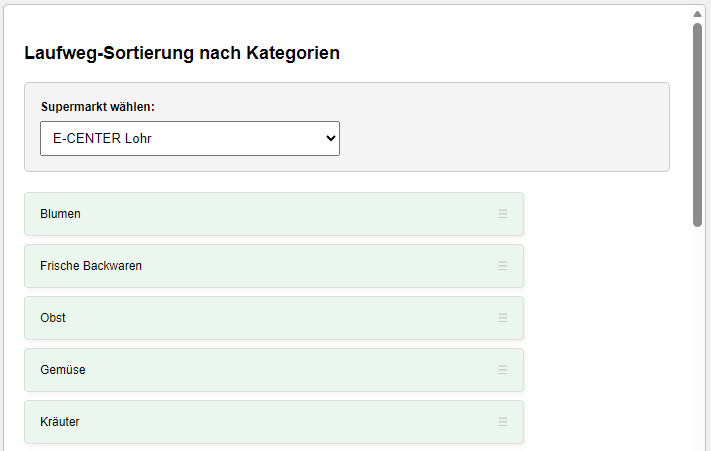
Dann muss man diese Produktgruppen nur noch in der richtigen Reihenfolge für den Supermarkt per Drag & Drop hinschieben.
Supermarkt wählen! Grüne Kacheln sind sortiert, weiße nicht. Nun ist alles eingestellt.
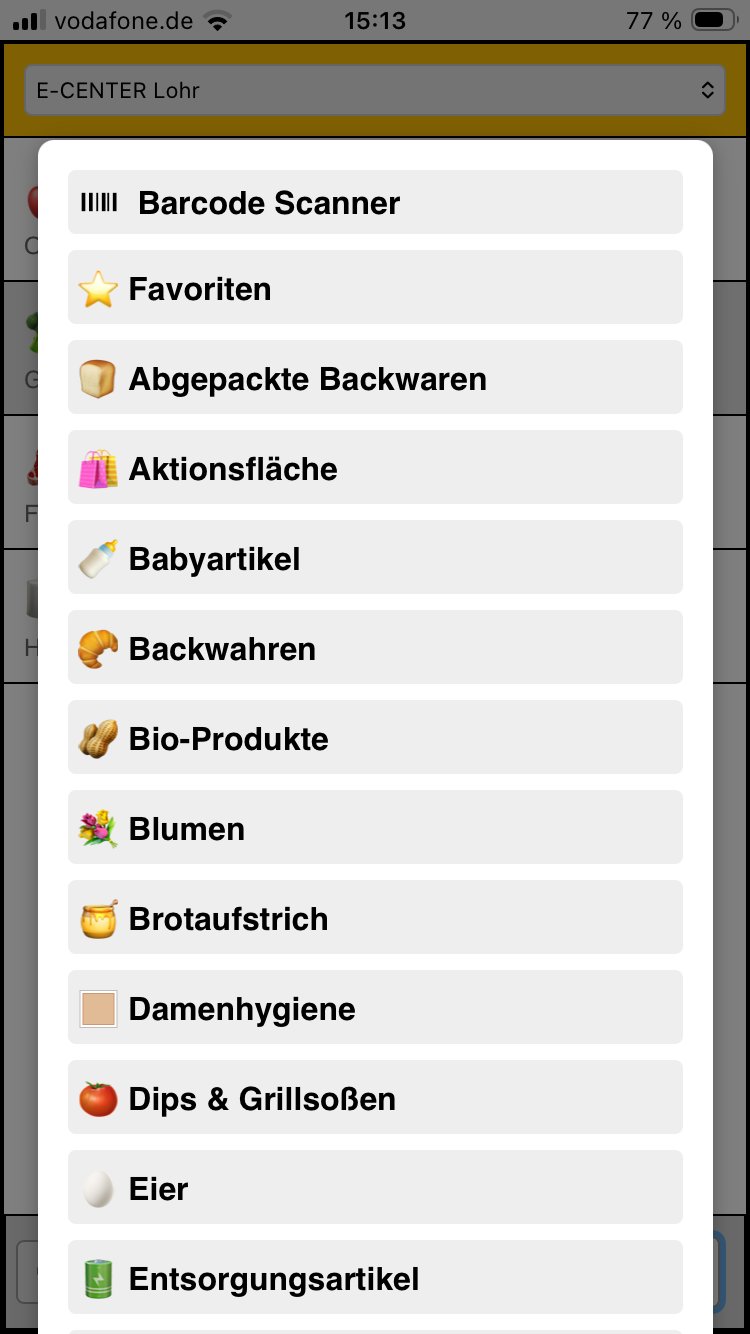
Für mobile Geräte habe ich das als Web-App gebaut. Nachdem die App auf dem Bildschirm ist
kann sie geöffnet werden. Hier ist das Funktionsprinzip das gleiche, nur eben auf Touch optimiert. Nachdem alles eingestellt ist, kommt eine weitere interessante Funktion dazu. Beim klick auf das + öffnet sich ein weiteres Overlay. Hier kann man die Produkte direkt aus der Kategorie auswählen. Produkte die man häufiger benötigt findet man auch in den Favoriten wenn man diese gesetzt hat.
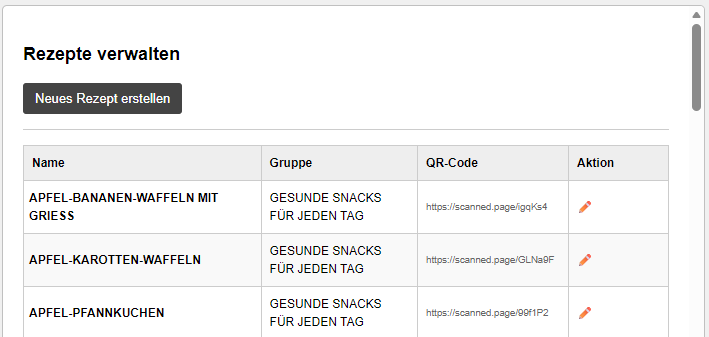
Zu guter Letzt gibt es noch den Barcodescanner den man in dieser Auswahl findet. Hier habe ich bereits erklärt worauf ich hinaus will. Ein weiterer Menüpunkt ist die Rezeptverwaltung.
Hier kann man Rezepte anlegen, und diesen Produkte zuweisen.
Hier gibt es das Produkt welches eine Zutat, eine optionale Zutat oder ein Gewürz sein kann. Mange, Einheit und Zusätzliche Informationen. Die Reihenfolge im Rezept kann man zudem noch einstellen. Hierfür habe ich die oben erwähnte API eingebaut. Man kann json in der richtigen Struktur direkt an die Schnittstelle schicken. Dann wird ein Rezept angelegt und die dazugerigen Produkte. Diese werden sofort geprüft, und wenn noch nicht vorhanden angelegt. So hat mein Rezept-Agent bisher 150 Rezepte mit den passenden Produkten in die Datenbank geschrieben. Zurück zum Scanner.
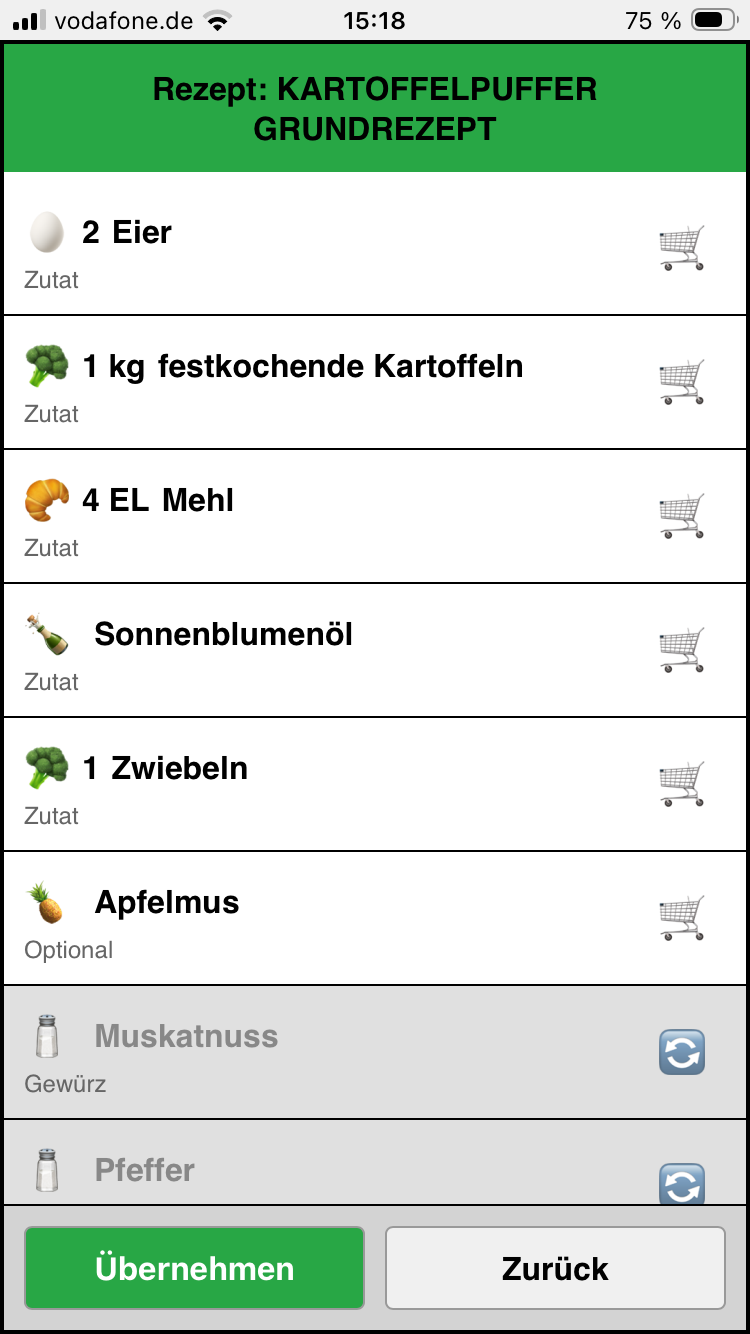
Barcode scannen. Wenn das Rezept richtig angelegt ist, findet er die Produkte.
Zutaten und Optionale Produkte werden zum Einkaufen vorselektiert, Gewürze nicht. Mit einem klick kann man korrigieren was man in der Einkaufsliste haben will. Über den Button Übernehmen werden die Markierten Produkte zur Einkaufsliste hinzugefügt. Das System lässt sich vielseitig einsetzen.
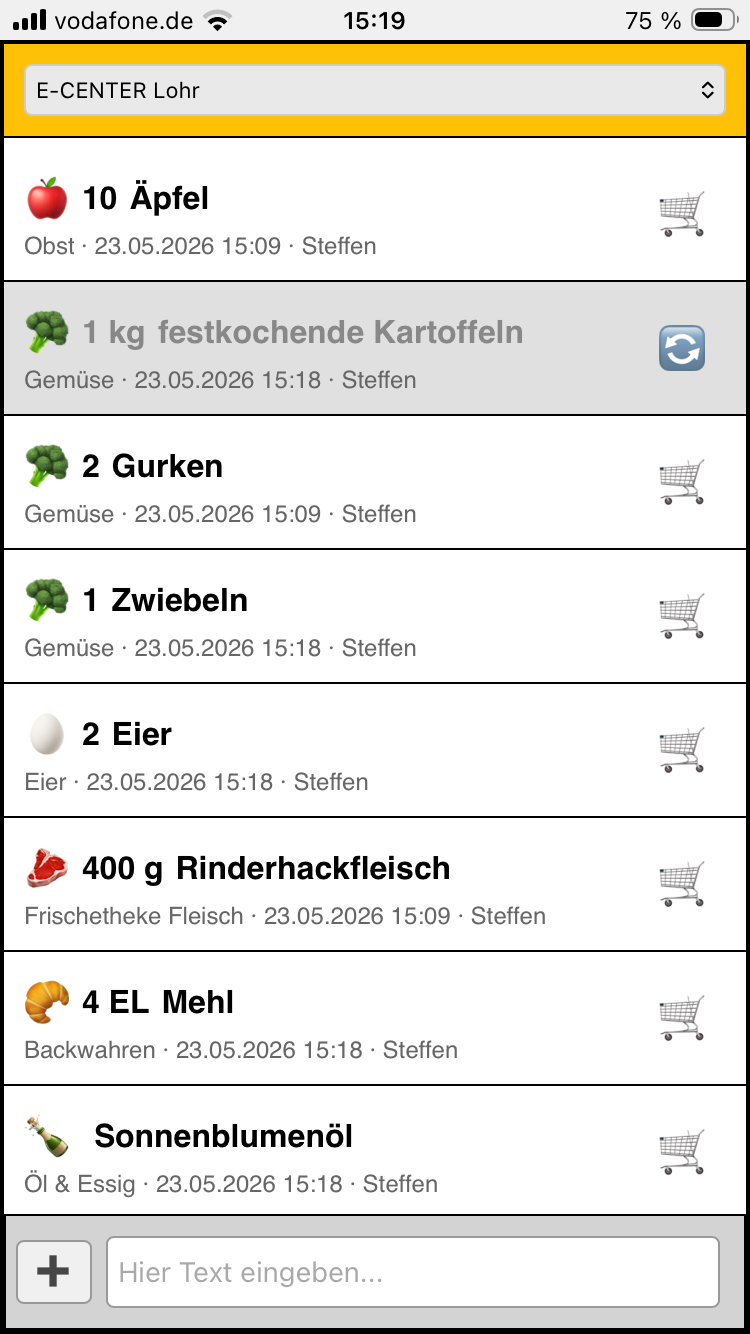
So, nun zum Einkaufen. Durch einen klick auf den Einkaufswagen hat man das Produkt in den Einkaufswagen gelegt. Hier gibt es wieder einen Toggle Mechanismus. Stellt man fest das man etwas falsches in den Einkaufswagen gelegt hat, kann man dieses durch erneutes klicken wieder Herausnehmen. Rausgehend werden nur die Daten des einen Produkts an den Webserver geschickt, eingehend bekommt man die gesamte Liste, um zu synchronisieren, wer sonst noch etwas eingekauft hat, oder gegebenenfalls etwas zusätzliches in die Einkaufsliste getan hat. Alles läuft über AJAX wodurch die Datenmenge stark reduziert ist. Es soll ja auch gehen wenn man mal schlechten Empfang hat.
Sind zu guter Letzt alle Produkte als Eingekauft markiert, werden diese in eine andere Tabelle verschoben, und die Einkaufsliste ist leer. Die historischen Einkäufe kann man sich dann auf einer weiteren Seite anschauen.
Ein Artikel über Meta, den ich im Internet gelesen habe, und die Aufgabe eines Trainees bei uns in der Firma hat mich dazu gebracht mir das Thema AI Agent’s anzuschauen. Vorweg möchte ich alle die das lesen dazu motivieren, sich aktiv mit dem Thema AI auseinanderzusetzen. Ich befürchte das alle, die jetzt nicht auf den Zug aufspringen, über kurz oder lang unter die Räder ebenjenes kommen. Die Tragweite meiner Aussage ist mir durchaus bewusst. Die aktuelle Entwicklung ist menschlich keine gute wie ich finde, aber die großen Player haben die Büchse der Pandora aufgemacht, und diese werden wir alle nicht mehr schließen können. Deshalb heißt es, mitschwimmen, den Kopf über Wasser halten, sonst säuft man ab. Das zeigt das Beispiel Meta. Hier ersetzen gerade KI Agent’s 8000 Mitarbeiter und Führungskräfte. Und das innerhalb von 4 Monaten Entwicklungszeit. Ob ich mit meinen Gedanken richtig liege wird die Zeit zeigen.
Solange schwimmen wir mal los … Die Funktionalität welche die großen Firmen gerade nutzen, kann man auch selbst als DIY Bastler hervorragend verwenden. Ich will das folgend an einem Beispiel zeigen und für Anregung sorgen. Ich weiß das ihr auf allerhand großartige Ideen und pfiffige Lösungen kommt, und freue mich schon darauf mich mit euch über eure Anwendungsfälle zu Unterhalten.
Für ein Projekt an dem ich gerade arbeite benötige ich Informationen die auf kleine Karten gedruckt sind. Diese sollen ausgelesen und als JSON zur Verfügung gestellt werden. Dazu habe ich einen Agent gebaut, was recht simpel war. Zunächst einmal die Ordnerstruktur und die Dateien anlegen.
In der Datei agent.py ist das Python Script für den Agent. In .env ist der API-Key gespeichert. Diesen kann man sich unter aistudio.google.com holen.
Sobald man einen API-Key hat, kann man prüfen welche Modelle einem zur Verfügung stehen
Python:
# Test-Script zum Auflisten der Modelle
for model in client.models.list():
print(f"Name: {model.name}, Supported Methods: {model.supported_actions}")
Für Gemini 1.5 Flash beispielsweise sind die kostenlosen Limits folgendermaßen: Rate Limit: Bis zu 15 Anfragen pro Minute (RPM). Tageslimit: Bis zu 1.500 Anfragen pro Tag (RPD). Token-Limit: 1 Million Token Kontextfenster.
Jetzt schreibt man einen Prompt für die Aufgabe die der Agent ausführen soll:
Prompt:
Du bist ein spezialisierter Assistent zur Datenextraktion aus Bilddateien. Deine Aufgabe ist es, Informationen von einer Rezeptkarte in ein präzises JSON-Format zu überführen.
Analyse der Bildbereiche:
Rezeptname: Befindet sich oben links in der weißen Box.
Rezeptgruppe: Befindet sich oben rechts in der weißen Box.
QR-Code: Befindet sich unten in der Mitte.
Zutaten: Liste auf der rechten Seite unter der Überschrift "Zutaten".
Optionale Zutaten: Falls vorhanden, unter der Überschrift "Optional".
Gewürze: Falls vorhanden, unter der entsprechenden Überschrift.
JSON-Strukturvorgaben:
Verwende exakt die folgende Struktur. Wenn eine Kategorie fehlt, setze null oder [].
Achte darauf, Menge und Einheit korrekt zu trennen. Falls keine Einheit angegeben ist, verwende null.
Wichtig: Gib als Antwort ausschließlich den reinen JSON-Code zurück. Keine Erklärungen, kein Markdown-Code-Block.
{
"rezeptname": "String oder null",
"rezeptgruppe": "String oder null",
"qr_code": "String oder null",
"zutaten": [],
"optional": [],
"gewuerze": []
}
Zuguterletzt fehlt noch das Python Script, wofür zusätzliche Pakete benötigt werden.
Das Script schaut im Ordner img_new ob es dort Bilder gibt. Die Bilder werden geladen und an das Model übergeben. Das Ergebnis wird als JSON File gespeichert und das Bild entweder als erledigt in den vorgesehenen Ordner geschoben oder in den Error Ordner.
Das Sahnehäubchen bildet inotify welches in jedem Linux Kernel integriert ist. Um es zu nutzen verwenden wir inotify-tools
Vor ein paar Tagen habe ich mir für meinen Energieüberschuss auf Empfehlung von bis dahin zwei Kollegen eine Zendure 1600 AC+ gekauft. Eigentlich wollte ich mir meinen Speicher selbst bauen, aber man muss ja nicht für alles das Rad neu erfinden. Nun ist es leider so, das man die Kiste nur mit dem in der Firmware hinterlegten MQTT Broker verbinden kann. Meine Meinung zu Home-Automation ist strikt. Das Wort steckt schon im Begriff, nämlich „Home“. In diesem Zusammenhang kann ich mit dem ganzen IoT und Cloud Wahn überhaupt nichts anfangen. Es ist ja schließlich auch noch niemand auf die Idee gekommen, das eigene Stromkabel zu Hubel-Heiner-Butzenbach den ich mal Bernd nenne und der zwei Straßen weiter wohnt zu legen, dort in einen Schaltkasten, und von dort wieder zurück. Um den eigenen Treppenhausautomaten dort unterzubringen, damit Bernd immer schauen kann wann ich in den Keller gehe und das zu protokollieren. Der Clou an Bernd und anderen Anbietern wie Shelly, Bosch, Zendure uvm. ist, das man sich seine live Daten anschauen kann (Ahhh das Licht ist an!) die Historischen Daten aber in Bernds Tresor landen, und mir diese nicht frei zur Verfügung stehen. Wie wenn das Bernds und nicht meine Kellergänge gewesen wären. Und wenn der Bernd glaubt, nicht genug dran zu verdienen, oder keine Lust mehr hat, schaltet er einfach meinen Treppenhausautomaten ab. Bernd argumentiert dann: Trotz aller Bemühungen und des innovativen Konzepts wurde nicht die für einen wirtschaftlichen Weiterbetrieb erforderliche Marktakzeptanz erreicht!
Wo war ich stehen geblieben? Ah ja, wer sagt denn, das ich meinem Server in meinem lokalen Netzwerk nicht den alias mqtt-eu.zen-iot.de geben kann und somit die Zendure 1600 AC+ mit meinem MQTT spricht?! Das eine nennt man Spoofing und das andere Hijacking was garnichtmal so trivial ist.
Da ich das nicht über meinen Linux Server lösen, dort Sicherheitslöcher aufreißen und etliche vorhandene, funktionierende Sachen verbiegen wollte, habe ich mich für einen anderen Weg entschieden. In meiner Bastelbox liegen seit ein paar Tagen zwei brandneue ESP32 S3 DevKit1 R16N8. Mit 16MB Flash und 8MB PSRAM haben die um einiges mehr Ressourcen als meine bisherigen. Sollte also für eine TCP-Bridge reichen.
Also erst mal schauen was alles von Zendure erwartet wird. HTTP Token (TCP), MQTT (TCP), NTP (UDP) oha. Ohne Uhrzeit lässt sich die 1600 AC+ nicht regeln.
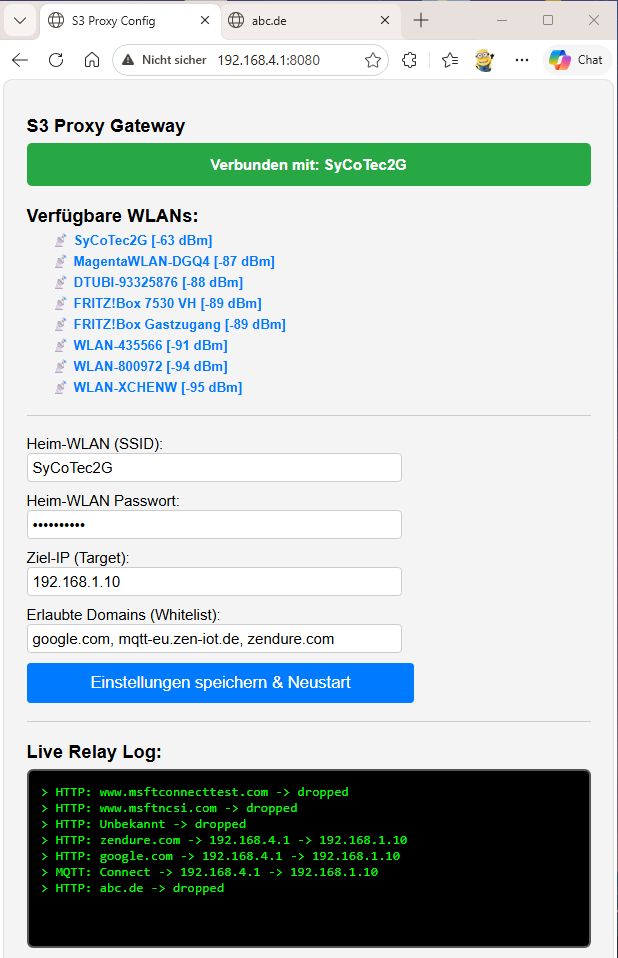
Erst mal mit dem Programmieren anfangen. Zunächst einmal einen Accesspoint mit WPA aufspannen. Zum Testen auf 192.168.4.1 (default) und über das Webinterface auf Port 8080 konfigurierbar machen. Dann nach SSIDs scannen und das Zielnetzwerk einstellbar machen. Zudem die Target IP also mein persönlicher Server einstellbar machen. Zum Testen wird die 192.168.1.10 verwendet. Zur Sicherheit habe ich eine Whitelist eingebaut. Nur erlaubte Domains dürfen auf meinen Server. Um das zu prüfen musste noch ein Log ins Interface. Dann noch DNS und TCP einbauen.
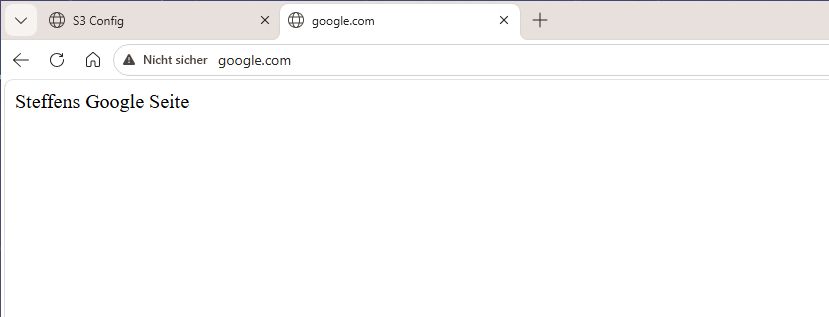
Was passiert nun? Der Client meldet sich am ESP32 Accesspoint an, bekommt den Gateway und den DNS 192.168.4.1 sowie eine freie IP in diesem Netzwerksegment. Wenn der Client nun beim DNS nach der IP von Beispielsweise google.com fragt, bekommt er die 192.168.4.1 zurück insofern die Domain in der Whitelist ist. Intern werden die Pakete über die TCP-Bridge welche die WIFI Klasse mitbringt an die Target-IP weitergeleitet, und von da die Antwort zurück.
Funktioniert astrein.
Bei NTP schaut die Sache nun anders aus. Das User Datagram Protocol (UDP) hat zwar einen Header, aber dieser beinhaltet keine Quell und Zieladressen. Die werden eine Schicht darüber im IP-Header geführt. Das ist in meinem Fall ein Problem. Der Client schickt die Anfrage zur .4.1 wo es ausgepackt wird. Hier sieht mein Proxy das es eine NTP Anfrage auf Port 123 ist. Dieses kann ich nehmen, und auf der anderen Seite wieder als UDP an meinen Server, den Router oder einen anderen NTP-Server schicken welcher mit der Uhrzeit antwortet. Da aber der ESP32 vergessen hat von wem die Anfrage gekommen ist, endet der Rückweg hier. Es muss ein simuliertes abgespecktes Network Address Translation (NAT) her. Also habe ich eine Funktion für NAT-light eingebaut. Das hat soweit geklappt, benötigt aber viele Ressourcen und bremst den Proxy aus. Zudem ist das System unzuverlässig sobald zwei Clients UDP anfragen stellen, da der eine den anderen im schlechten Fall überschreibet. Also habe ich rumgekämpft, die NAT-Funktion weiter aufgeblasen um das System noch langsamer zu machen. Hat mir alles nicht gefallen. Beim drüber schlafen habe ich mir die Sache nochmal durch den Kopf gehen lassen. Wenn doch der Client eh nur die .4.1 sieht, dann kann er doch von da auch die Urzeit bekommen. Und so läufts. Der ESP32 holt sich beim Boot und in regelmäßigen Abständen die Uhrzeit bei de.pool.ntp.org und stellt sie selbst als NTP zur Verfügung.
Bernd, wenn du dich persönlich angegriffen fühlst, möchte ich mich dafür entschuldigen. Der Name ist Rainer Zufall! Äh nein Rainer, nicht ganz. Welches international agierende Unternehmen mit dem Hang zur Verlagerung beginnt nochmal mit dem gleichen Buchstaben?
Warum nicht direkt NAT verwenden. Weil die Klasse gekapselt ist, und Eingriffe wie ich sie benötige nicht hergibt ohne diese umzuschreiben.
NTP beinhaltet nicht nur die Uhrzeit. Uhrzeit war aber einfacher zu schreiben.
Es ist zu erwähnen das google.com für meine ersten Tests die schlechtmöglichste Wahl war. Aber man lernt nie aus. Moderne Browser sind sogenannte HSTS Browser. Beim Aufruf einer Website kann diese dem Browser mitteilen, das zukünftig oder für eine gewisse Zeit der Verbindungsaufruf auf eine andere Adresse umgeändert wird. Es ist gar nicht so einfach dem Browser zu sagen das er bei google.com nicht https://www.google.com/?hl=de aufrufen soll.
Eigentlich ist dies ein Beitrag, den ich nie schreiben wollte.
Ich hatte eine einfache Grundregel: Auf diesem Blog erkläre ich keine Systeme oder Werkzeuge, die — unabhängig von ihrer technischen Legitimität — auch gezielt von Kriminellen eingesetzt werden, um Straftaten zu verschleiern. Nicht, weil ich diese Werkzeuge ablehne, sondern weil mir bewusst ist, dass Wissen Verantwortung bedeutet.
Und dennoch schreibe ich heute über die Einrichtung von Mullvad VPN.
Der Grund dafür ist kein technischer, sondern ein politischer.
Was für mich das Fass zum überlaufen gebracht hat, war vor ein paar Tagen die Aussage von Bundeskanzler Friedrich Merz auf einer Konferenz in Trier, in der er das Internet ausdrücklich als politischen Debattenraum bezeichnete und daraus die Notwendigkeit einer Klarnamenspflicht ableitete. Spätestens an diesem Punkt wurde mir klar, dass sich ein grundlegendes Missverständnis festgesetzt hat: Das Internet wird von Teilen der Politik offenbar nicht als Infrastruktur verstanden, sondern als eine Art öffentlicher Marktplatz.
Doch das World Wide Web ist kein Marktplatz.
Es ist der größte, offenste und zugleich gefährlichste Kommunikationsraum, den es gibt. Dort bewegen sich Staaten, Unternehmen, Nachrichtendienste, Betrüger, Datensammler und organisierte Kriminalität zugleich. Wer sich verbindet, exponiert sich technisch. Diese Realität verschwindet nicht dadurch, dass man sie politisch anders bezeichnet.
Deshalb bin ich der Meinung nicht die Nutzung von Schutzmaßnahmen ist erklärungsbedürftig, sondern ihre Nichtnutzung.
Die Entwicklung der letzten Jahre
(EU) 2016/679 – Ein Teil dieser Entwicklung begann mit der Datenschutz-Grundverordnung. Die DSGVO hatte ein legitimes Ziel: Bürgern bewusst zu machen, dass ihre personenbezogenen Daten nicht herrenlos sind und dass sie ein einklagbares Recht darauf haben, dass Daten gelöscht werden können. Dieser Gedanke ist richtig. Gleichzeitig waren die wirtschaftlichen Folgen erheblich. Zurückhaltende Schätzungen gehen davon aus, dass allein die Umstellung die deutsche Wirtschaft 50 Milliarden Euro gekostet hat, ohne die laufenden Kosten zu betrachten. Kosten, die letztlich über die Preise beim Bürger landen. Man muss festhalten: Die DSGVO hat nicht das grundlegende Problem gelöst, nämlich den technischen Selbstschutz des Einzelnen im Netz.
§ 188 StGB – Parallel dazu wurde § 188 erweitert, der besondere Ehrschutz für Personen des politischen Lebens. Kritiker sehen darin eine Ungleichbehandlung im strafrechtlichen Schutz persönlicher Ehre. In der Praxis hat sich zudem ein neues Phänomen entwickelt: automatisierte Auswertung öffentlicher Äußerungen im Internet und daraus resultierende juristische Verfahren. Unabhängig von der Bewertung zeigt das vor allem eines — Äußerungen im Internet sind längst kein flüchtiges Gespräch mehr, sondern dauerhaft verwertbare Information.
§ 113 TKG – Schon heute müssen alle Telekommunikationsanbieter Verbindungs- und Metadaten für 14 Tage speichern. Über Jahre wurde politisch über die anlasslose Speicherung gestritten – offiziell aus Gründen der Strafverfolgung und Gefahrenabwehr, faktisch aber ein Generalverdacht gegenüber allen Nutzern. Geplant ist nun eine Ausweitung auf drei Monate, was nicht nur zusätzliche Kosten für die Verbraucher bedeutet, sondern den praktischen Nutzen infrage stellt: Überlastete Gerichte können die Daten kaum zeitnah auswerten. Gleichzeitig steigt das Risiko, dass sich auch hier eine Klageindustrie entwickelt, die automatisiert auf kleinste Verstöße reagiert, da die geplanten Änderungen neue Angriffspunkte schaffen.
Aus den beschriebenen Entwicklungen ergibt sich ein grundlegender Widerspruch: Während Bürger zunehmend verpflichtet werden, identifizierbarer zu werden, wächst gleichzeitig die Bedrohungslage im Netz gerade in Zeiten von KI enorm. Daten und Identitätsdiebstahl, Social-Engineering-Angriffe und automatisierte Betrugssysteme sind Alltag.
Verhältnismäßigkeit und Realität
Wenn ich das Internet mit einem physischen Ort vergleichen müsste, dann wäre es kein offener Marktplatz — sondern eher eine dunkle, unübersichtliche Gasse sichtbarer und unsichtbarer Akteure. In einer solchen Umgebung dürfte niemand ernsthaft fordern, das ein Kind ein Schild tragen muss auf dem steht: „Ich bin Susi, 12 Jahre alt“
In der analogen Welt existierten schon vor dem Internet Schutzprinzipien:
• das Briefgeheimnis (Art.10 GG), • die Vertraulichkeit der Telekommunikation (TKG §88-91), • das Recht sich frei zu versammeln (Art.8 GG), • das Recht auf Anonymität abgeleitet aus (Art.2 Abs.1 Grundgesetz)
Niemand verlangt, dass auf jedem Brief außen der vollständige Lebenslauf steht. Niemand würde akzeptieren, dass jede Postverbindung pauschal protokolliert wird. Und doch bewegen wir uns im Internet zunehmend in genau diese Richtung.
Die eigentliche Fehleinschätzung ist daher nicht technischer, sondern struktureller Natur: Das Internet ist keine Debattenplattform — es ist Infrastruktur. Und Infrastruktur benötigt Sicherheit.
Warum dieser Artikel existiert
Ich breche mit meiner eigenen Regel, weil sich die Rolle verschoben hat.
Früher bedeutete die Erklärung von Anonymisierungs- oder Schutztechniken jemandem beim Verbergen zu helfen. Heute bedeutet das Weglassen dieser Informationen zunehmend, Menschen ungeschützt zu lassen. Zwischen Verschleierung und Selbstschutz besteht ein entscheidender Unterschied.
Meine persönliche Schlussfolgerung ist daher einfach:
Sobald ich eine Verbindung mit dem World Wide Web herstelle, öffne ich eine Tür zu einem potenziell gefährlichen Raum. Das muss jedem bewusst sein — auch politischen Entscheidungsträgern. In diesem Raum geht es um Sicherheit und vor allem um Eigenschutz. Und wenn staatliche Maßnahmen diesen Schutz nicht gewährleisten oder ihn sogar verringern, dann bleibt nur eine Konsequenz:
Ich muss mich und meine Familie selbst schützen.
Vorbereitung
Im folgenden erkläre ich unabhängig meines eigenen VPN-Gateways die Einrichtung von Mullvad VPN auf einem Raspberry PI mit nur einem Netzwerkadapter.
Voraussetzungen: • Router 192.168.100.1 • Raspberry PI 192.168.250.250, 192.168.100.250 • Raspberry PI OS (Debian) vorinstalliert • A klitzeklois bissle Ahnong vo Linux du Dackel
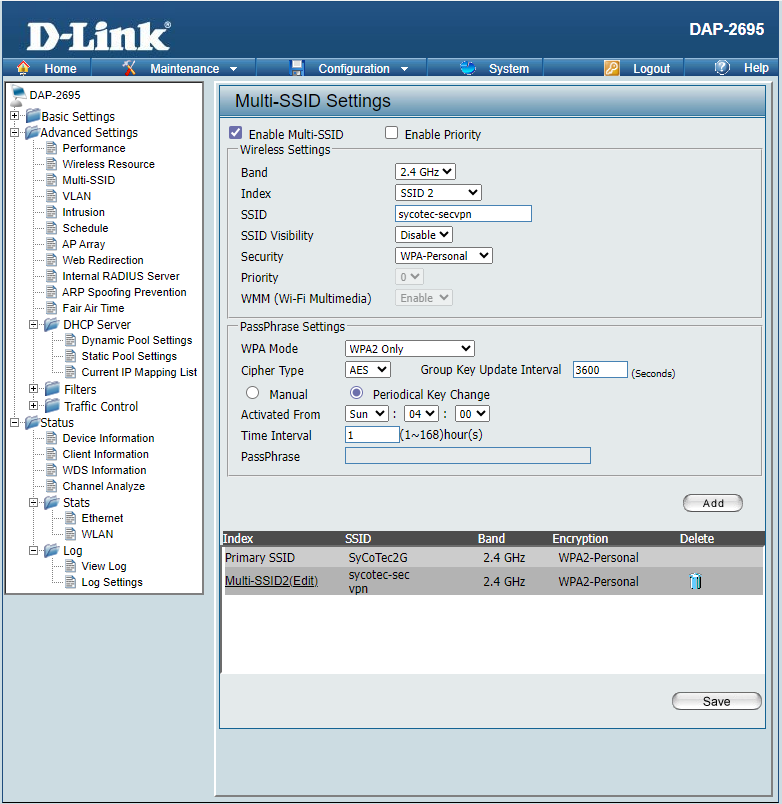
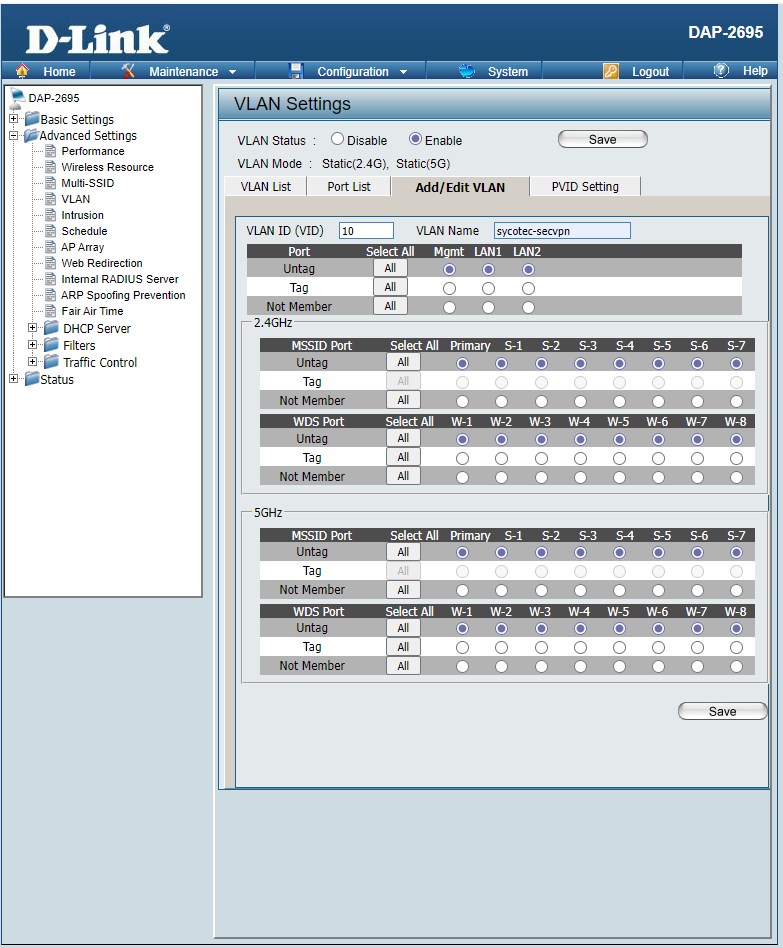
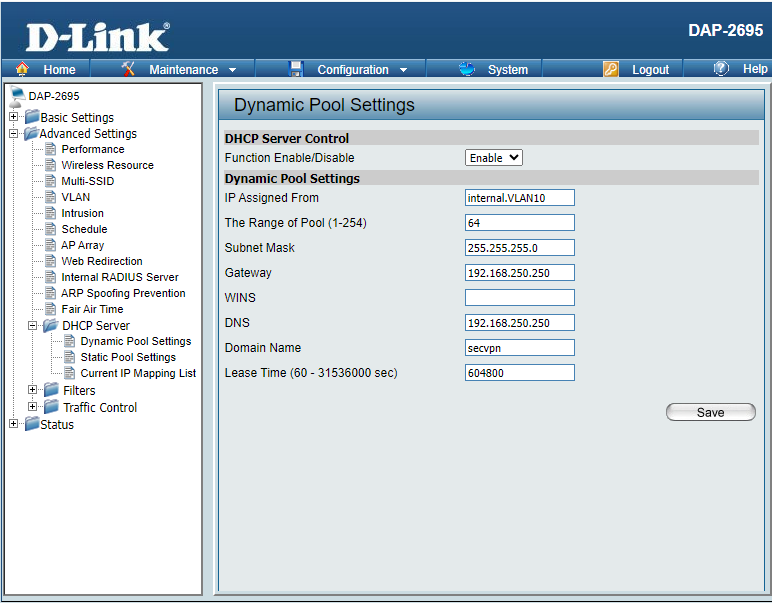
Zunächst muss die Möglichkeit geschaffen werden, dem Client den Raspberry PI als Gateway vorzugeben. Eine Möglichkeit ist es, IP Adresse, Gateway sowie DNS am Client fest einzustellen. Ich möchte eine flexiblere Lösung aufzeigen. Der D-Link DAP2695 beispielsweise bietet dafür eine Ausgezeichnete Möglichkeit. Zunächst legt man eine Zusätzliche SSID an, in meinem Fall sycotec-secvpn. Danach ein virtuelles logisches Teilnetzwerk, hier VLAN10. Diesem weist man über SSID-to-VLAN Mapping die neue SSID zu. Danach muss noch der DHCP konfiguriert werden.
SSIDVLANDHCP
Bei dieser Konfiguration ist es nun so, das der WLAN-Client bei der default SSID die Netzwerksettings vom DHCP des Routers bekommt. Verbindet man sich über die SSID sycotec-secvpn erhält man die Netzwerksettings vom DHCP des Accesspoints, landet im Segment 192.168.250.0 und bekommt den Raspberry Pi als Gateway.
Einrichtung des VPN Gateways
Idealerweise macht man zunächst ein Update der Paketliste und des Betriebssystems
sudo apt update
sudo apt upgrade -y
um danach die neusten Pakete von wireguard, nftables, dnsmasq und curl zu installieren, falls noch nicht vorhanden.
Folgend muss der Pi in die beiden Netze IN (192.168.250.250) und OUT (192.168.100.250). Dazu wird /etc/network/interfaces wie folgt geändert:
auto eth0
iface eth0 inet static
address 192.168.100.250
netmask 255.255.255.0
gateway 192.168.100.1 # IP des Routers
dns-nameservers 192.168.100.1
# Virtuelles Interface für secvpn Subnetz
auto eth0:1
iface eth0:1 inet static
address 192.168.250.250
netmask 255.255.255.0
Der DNS Server spielt an dieser Stelle für den VPN keine Rolle. Damit Linux Routen kann, muss IP Forwarding unter /etc/sysctl.conf aktiviert werden.
net.ipv4.ip_forward=1
Danach meldet man sich mit seinen Zugangsdaten unter https://mullvad.net/ an, und wählt dort „WireGuard configuration“. Ich habe mich für einen Ausgang in Island entschieden da diese eine Hervorragende Infrastruktur haben, und dort die Privatsphäre sehr hoch aufgehängt ist. Dafür wählt man
• Server location: Iceland • Device: Linux • Tunnel: WireGuard
aus und startet den Download. Den Inhalt der mullvad.conf kopiert man nun in die Datei /etc/wireguard/wg0.conf welche dann folgende Struktur hat:
Wichtig ist hier das AllowedIPs auf 0.0.0.0/0 steht, damit sämtliche Packete durch den Tunnel gezwungen werden. Nun können wir WireGuard probehalber schonmal starten und schauen ob der Tunnel funktioniert.
sudo wg-quick up wg0
curl https://am.i.mullvad.net/ip
Hier sollte nun Country: Iceland stehen. Wenn der VPN nicht läuft bekommt man lediglich die aktuelle Internet IP angezeigt. Wenn’s nicht geht, gehe zurück zum Start, gehe nicht über Los und ziehe nicht 200 Mark ein. Alles Punkt für Punkt überprüfen und schauen ob alle Dienste laufen. Ansonsten … weiter geht’s. Da wir nicht wollen, das uns der DNS verrät zwingen wir diesen auch durch den Tunnel und nehmen den DNS von Mullvad. Dazu editieren wir die Datei /etc/dnsmasq.conf
Wichtig bei der Nutzung eines VPN Gateways als „Router“ ist es sich vorher genau zu überlegen welche Endgeräte man durch den Tunnel schicken will und welche nicht. Darauf aufbauend muss man sich das Konzept überlegen. Hier gibt es für fast alles eine Lösung. Aber Achtung, Streaming Anbieter sind bei „Geo Blocking“ sehr empfindlich und auch die VPN Tunnel von Arbeitgebern mögen es zuweilen überhaupt nicht ihrerseits getunnelt zu werden. Ganz paranoide haben noch die Möglichkeit ihre DNS Abfragen mit dnscrypt-proxy über DoH (DNS over HTTPS) laufen zu lassen. Über diesen Vorschlag gab es bei ein paar Bierchen einen angeregten Austausch. Danke dafür.
Noch ein paar wichtige Tips: Wenn an den config-files von laufenden Diensten etwas geändert wird, müssen die Dienste zumeist neu gestartet werden. Die Regeln von iptables-persistent und netfilter-persistent müssen gespeichert werden um sie nach einem reboot noch zur Verfügung zu haben.
Nachdem bei mir viel Interesse am Thema AI bekundet wurde, habe ich die Fragen gesammelt. Dabei wurde mir klar, das die meisten noch keine Berührungspunkte mit LLM’s (Chatbots) also der Basis der häufigsten KI Anwendungen hatten.
Aus diesem Grund habe ich meinen Post Howto AI als Grundlage genommen und ein Tutorial für die Nutzung von ChatGPT erstellt. Da sich bis zur Fertigstellung des Tutorials nicht mehr viel zu diesem Thema in meinem Posteingang getan hat, lag das Teil nun eine ganze Weile ganz weit unten in meiner Schublade.
Kürzlich hatte ich dann eine interessante Unterhaltung mit einem Kollegen zu diesem Thema. Während dieser Unterhaltung kam raus, das die „Hemmschwelle“ sich bei OpenAI anzumelden das größte Hindernis für „Neulinge“ darstellt.
Also habe ich das Tutorial nochmal überarbeitet und Gemini als LLM verwendet, da man diesen direkt über die Google Startseite aufrufen kann.
Vor ein paar Tagen hatte ich eine Unterhaltung mit einem Freund bei der es um Add-Blocking ging. Ich habe ihm von DNS4EU aus meinem letzten Beitrag erzählt, und das diese je nach gewähltem DNS-Server schon Add-Blocking machen.
Er hat mir im Gegenzug von einem (bereits über ein paar Jahre gereiften) Tool namens PI-Hole erzählt welches er nutzt. Hört sich interessant an dachte ich mir, und muss ich dann mal testen.
Also habe ich das Tool installiert. Heidewitzka… Der Core lief auf Anhieb. Auf das Webinterface konnte ich nicht zugreifen. Als Tipp Vorweg, wer sich zum Testen Ärger ersparen will macht RasperryOS aka Debian 12 auf den PI und installiert direkt pihole.
Es hat mich geärgert und wenn mich was ärgert will ich das gelöst haben. Der übliche Chatbot konnte mir nicht helfen, weil er fest davon überzeugt war, das lighttpd als Webserver verwendet wird. Ok, dachte ich mir. Ich hab Apache2 also wofür benötige ich noch einen Webserver. Wie sich herausstellte war lighttpd auch nicht installiert. So konnten sich auch keine Ports gegenseitig blockieren. Und ich konnte 80 und 443 auch nicht auf 8080 und 4443 verschieben wie empfohlen. Also das Webinterface neu installiert und geschaut was da passiert. Er holt sich die Files aus nem Git und kopiert sie nach var/www/html/admin. Dort lagen dann die Files als *.lp „Lua Pages“ ab. Gut dachte ich, installiere ich halt die Apache Erweiterung für Lua Pages. Pustekuchen „Dieses Modul steht für ihr System nicht zur Verfügung oder ist Abgelaufen. Ahhhhhh….
Nach längerem Suchen habe ich dann herausgefunden das pihole ab v6.2 einen integrierten Webserver Namens CivetWeb verwendet. Also von vorn, Apache2 stoppen, /admin aus dem DocumetRoot löschen, pihole Installationsscript erneut aufrufen. pihole-FTL stoppen. Nun kann man in der pihole.toml den Port ändern. Die richtige Syntax ist
port = "8080o,4443os,[::]:8080o,[::]:4443os"
Apache2 wieder starten, pihole-FTL wieder starten, und einloggen!
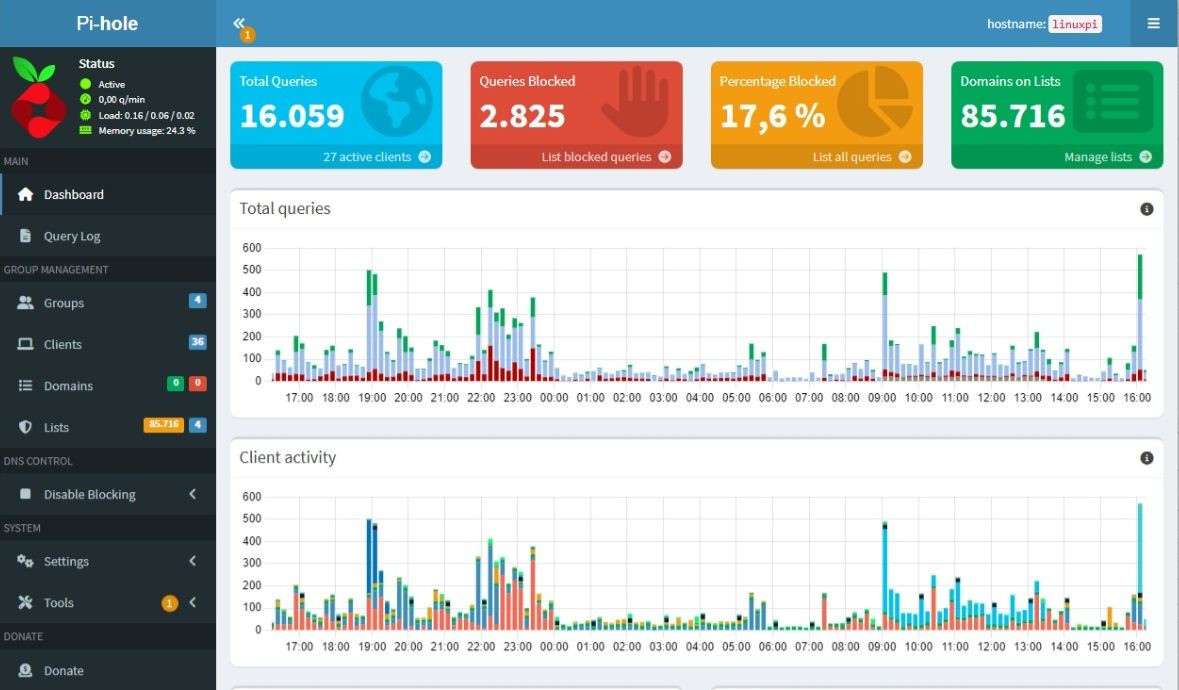
Es ist verrückt. 22% geblockte Inhalte. Aber nicht nur das. Selbst beim Streaming *kann* größtenteils die Werbung entfernt werden. Der ultimative Test ist hier die Website heise.de Hier kann man optisch prima sehen, das es zwischen DNS4EU – Ad Blocking und Pi-Hole noch merkliche Unterschiede gibt.
Aktueller Stand 17.12.2025:
Inzwischen hat wieder jedes Subnet seine eigene „DNS Konfiguration“.
Bekannte Geräte Zone Bekannte Geräte Kinder Zone Bekannte Geräte IoT Geräte Zone Unbekannte Gast Geräte
Realisieren kann man das über die Gruppenfunktion in der GUI und der Clientzuordnung. Alle DNS anfragen von Clients die Internetfreigabe haben, werden zum PI-Hole gezwungen und von da direkt über DoH zu DNS4EU TYP2. Fehlt nur noch das Script das die MAC Adressen aus der dhcpd.conf ausliest und in die gravity.db von Pi-Hole einträgt.
Domains oder Subdomains lassen sich im Menüpunkt Domains white oder blacklisten. Ich finde es allerdings einfacher das über die verwendeten Blocklisten zu machen.
Ergänzend:
Da es doch einige Fragen zu diesem Post gab: Um mich hier nicht angreifbar zu machen habe ich die Formulierung in meinem Post an einer Stelle leicht geändert. Des weiteren würde ich natürlich nie Werbung von Streaming-Diensten blockieren.
Ein klitze kleines bisschen Sarkasmus ist zu spüren ja, aber nichts desto trotz gibt es bei mir keine Anleitung um Werbung beim Streaming zu blockieren.
Gerne verweise ich auf die Website https://firebog.net wenn es um Blocklists geht. Hier ist mit Sicherheit für jeden was dabei. Und der erste Teil des Domain Namens ist reiner Zufall 😉
Bei einer Abteilungsfeier zu der ich eingeladen war hat mir ein Arbeitskollege von einem neuen großen DNS-Resolver für Europa „aus Europa“ erzählt. Das hat sich alles sehr Interessant angehört, und mir sind da gleich allerhand Schandtaten dazu eingefallen. Zuhause angekommen habe ich mich dann direkt mit DNS4EU beschäftigt. Details gibt es auf deren Website.
TYP 3: Protective Resolution with Child Protection
TYP 4: Protective Resolution with Ad blocking
TYP 5: Protective Resolution with Child Protection & Ad blocking
Das hat sich prima mit drei laufenden Aktivitäten ergänzt. Zum einen war ich dabei meine Infrastruktur für den kommenden Glasfaserausbau zu optimieren/erweitern. Zum anderen wollte ich meinen Raspberry-Pi mit Home Assistant rauswerfen und durch eine DIY Plattform ersetzen, da dieser mir schon 4 SD-Karten ruiniert hat. In diese Plattform wollte ich die Informationen meiner Homematic Zentrale mit einfließen lassen wo wir beim Punkt drei sind. Die CCU2 durch Raspberrymatic ersetzen. Also habe ich zuerst zwei Gehäuse für die PI’s gedruckt.
Diese eingebaut und in Betrieb genommen.
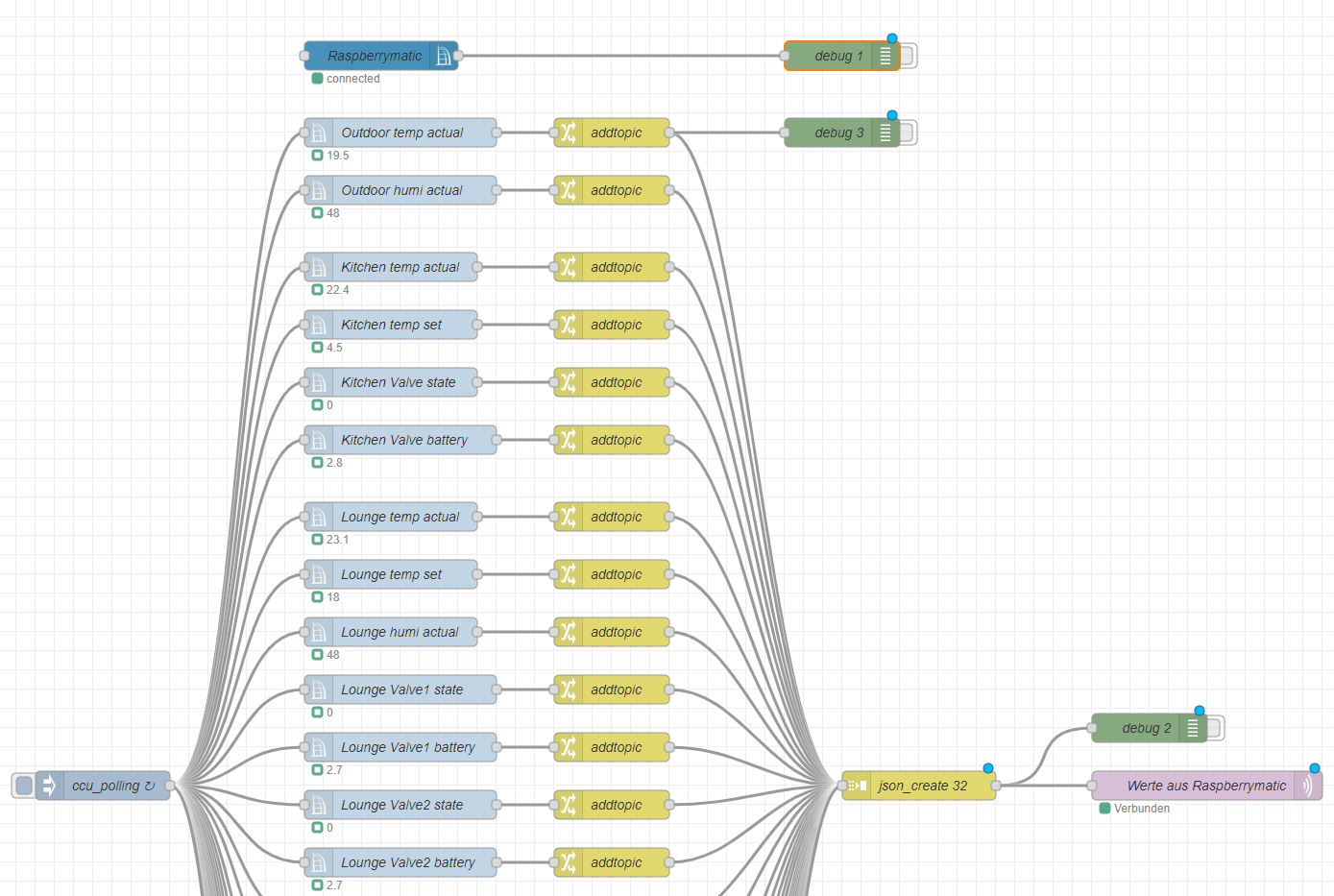
Der erste ist für Raspberrymatic zuständig.
Hier werden alle Homematic Komponenten gesteuert, und über eine API zur Verfügung gestellt. Das neu Anlernen, Verknüpfen und Einstellen der 2 Millionen Aktoren und Sensoren war nervig und zeitraubend aber ist kein Hexenwerk.
Als nächstes habe ich Debian auf den zweiten Pi installiert. Dazu kamen dann einige Pakete, welche ich zur Verfügung haben wollte. Standard sozusagen ist SSH und Samba. Dazu wollte ich einen Apache2 Webserver inklusive php Lib, mySQL und phpMyAdmin zum lokalen Testen von Code. Als MQTT Broker läuft nun Mosquitto um den bereits überlasteten Broker auf meinem ESP32 zu ersetzen, und Node Red um die fertige Schnittstelle zur Raspberrymatic API zu nutzen.
Das war bis dahin nicht der Rede Wert und auch keinen Beitrag wert da im Prinzip alles fertiges Zeug war oder nur Polygone schupsen im Node Red. Nun wollte ich die neuen Infos zu DNS4EU für mich nutzen und meine Ideen umsetzen. Also habe ich zunächst die config meiner alten iptables Firewall aus ISDN Zeiten rausgesucht die Basti damals mit mir erstellt hat. Danach habe ich mir IP-Bereiche (Subnets) überlegt:
Bekannte Geräte Zone Dürfen ins LAN und ins Internet und erhalten den DNS4EU: TYP 4 Bekannte Geräte Kinder Zone Dürfen ins LAN und ins Internet und erhalten den DNS4EU: TYP 5 Bekannte Geräte Proxy Zone Bspl. Onion Routing gegen Geoblocking und zum Anonymisieren Bekannte Geräte IoT Geräte Zone Dürfen nur ins IoT Zonen LAN Unbekannte Gast Geräte Dürfen nur ins Internet und erhalten den DNS4EU: TYP 2
Zunächst habe ich also die Zonen und alle MAC Adressen meiner Geräte in die dhcpd.conf eingetragen. In erster Linie wollte ich dafür sorgen das erstens die IoT Geräte in einer eigenen Zone sind, in der ich bestimme wer nach draußen darf. Zum anderen wollte ich für die Zukunft vorsorgen und eingrenzen, wo später die Kinder rumsurfen können. Dann habe ich mir überlegt was ich so als Jüngling getrieben habe, und dem wollte ich dann auch einen Riegel vorschieben. So bekommen Beispielsweise nur IP-Adressen die vom DHCP Server vergeben wurden einen accept-Flag. Das nennt sich Dynamic IP Hook. Dann ging es ans Eingemachte. Die Konfiguration von nftables welches iptables ablöst. Hier muss man zuallererst beachten, das die Ports 67 und 68 zum Linux Router frei sind und der Loopback (localhost) auf accept steht, sonst kommen die Clients beim connect nicht zum DHCP und somit bekommen sie keine IP und kein Lease. Es müssen die erlaubten (dynamic hook) DHCP-Clients eingebunden werden. Dann erst kommt der Forward-Chain (Packete von einer in eine andere Zone Leiten) und folgend die NAT-Tabelle (Network Address Translation) zum WAN. Hier ist an mancher Stelle einiges an Ausprobieren nötig bis alles funktioniert. Als Tüpfelchen auf dem i kommt noch ein Logging hinzu welches alle gedroppten Packete aufführt. Das geht nicht direkt. Die logs landen im Syslog (var/log/kern.log) und müssen mit rsyslog abgefangen und in die gewünschte Datei umgeleitet werden. Es ist erstaunlich wie viele ungewünschte Pakete an der Firewall verbrennen. Das war damals schon so, und ist heute nicht besser.
Anders als jetzt wäre ich mit meinem damaligen Wissen nicht an meiner heutigen Absicherung vorbei und mit eigenem DNS Server ins Internet gekommen, um nicht vom Jugendschutz ausgebremst zu werden. Wer mir Face2Face eine Möglichkeit aufzeigt, bekommt von mir ein Bier bezahlt 😉
Ein paar Anmerkungen noch:
By Default ist das syslog bei dem von mir gewählten Raspbeery OS (Debian) ausgeschaltet um nicht auf der SD-Karte rumzuschreiben wenn es nicht nötig ist. Beim Einschalten sollte man dafür sorgen das die Logs über eine Harte Verknüpfung auf einem USB-Stick landen.
Alle Files sind anonymisiert und nicht meine IP-Bereiche.
Alle Messwerte laufen nun über den neuen MQTT Broker und werden in meine IONOS SQL Datenbank geschrieben. Nun kann ich an meinem Backend mit Dashboards arbeiten.
der Datendurchsatz vom Pi und der Firewall liegt bei 260Mbit
die Stromaufnahme beider Pi`s zusammen liegt in Schnitt bei 5,6W
Von Fragen zu TOR, Mullvad oder redsocks ist Abstand zu nehmen!
Vom aktuellen Hype bezüglich Artificial Intelligence kurz AI oder auf deutsch KI kann man halten was man will. Die Produkte die auf Basis künstlicher neuronaler Netze entstanden sind liefern unumstritten erstaunliche Ergebnisse. Diese nicht zu nutzen wäre dumm.
Um diese Aussage einzuordnen möchte ich kurz meine Sichtweise auf die aktuell als künstliche Intelligenz gehandelten Computerprogramme erläutern. Meiner Ansicht nach handelt es sich nicht um künstliche Intelligenz. Ich vertrete den Standpunkt von Alan Turing. Dieser meinte das eine Maschine dann intelligent ist, wenn das Denkvermögen nicht von dem eines Menschen zu unterscheiden ist. Eine Gewichtung über eine Milliarde Datenpunkte ist eben nicht denken. Nun könnte man mit dem Argument kommen, das ChatGPT den Turing Test bestanden hat. Hier sollte die Frage erlaubt sein, ob ein Test der vor 70 Jahren ersonnen wurde um die damaligen Maschinen/Computer zu bewerten, heute der richtige Ansatz ist. Ich sage nur „Moore‘s law“. Für mich ist klar, das es durchaus Diskussionen zum Thema AI gibt und geben muss. Es muss auch viel mehr Regulierung stattfinden was man sehr gut beim Thema Suno-AI in den Medien verfolgen kann. Mit diesem Hintergrund und dem Wissen das nicht Cyberdyne Systems die KI entwickelt, plädiere ich dafür, AI zu nutzen, solange man nicht das Gefühl hat anderen zu schaden.
Folgend möchte ich zeigen wie man ohne Fachwissen zu KNN oder deep learning kostenlos AI Tools nutzen kann. Zunächst meldet man sich bei openAI an und startet ChatGPT. Zum Thema generative KI gibt es unzählige Fachbegriffe. Der erste für uns wichtige hier nennt sich Prompt. Das ist die Beschreibung dessen was man als Ergebnis haben will. Nun fordert man ChatGPT auf, einen Prompt zu erstellen, von dem was man auf seinem Bild sehen will. Das geht auch auf deutsch ganz gut. Ist man mit dem Text zufrieden kann man diesen Prompt ins englische übersetzen lassen, da die diversen Tools hier die genauesten Ergebnisse liefern. Mein simpler Prompt lautet:
a wide untouched snow surface in the foreground and the caves in the ross ice shelf in the background
Nun bitten wir ChatGPT aus diesem Prompt ein Bild zu erstellen. Aus dem Chat heraus wird DALL-E (openAI’s Bildgenerator) in der aktuellsten Version aufgerufen, welcher das Bild zurück liefert.
Ein wie ich meine beeindruckendes einzigartiges Bild. Folgend ein paar wichtige Informationen. Die Bildgeneratoren liefern das Ergebnis in 1024×1024, 1024×1792 oder 1792×1024. Die gewünschte Größe muss mit angegeben werden. Fordert man Chat-GPT ein weiteres mal auf, aus dem Prompt ein Bild zu erzeugen, wird man ein neues anderes Bild als Ergebnis bekommen.
Also kann man nicht an einem Ergebnis weiterarbeiten. Hier kommen wir zum zweiten Begriff, dem sogenannten Samen (seed) der bei DALL-E nicht zur Verfügung steht.
Hierzu gibt es andere spezialisierte KI-Tools. Um die Tools zu nutzen muss man diese nicht installieren oder bezahlen. Beispielsweise kann man sich bei Prompthero anmelden. Dort sucht man sich die Engine aus, mit der man arbeiten will. Beispielsweise Stable Diffusion. Nun bittet man ChatGPT den Prompt dafür zu optimieren. Der Prompt an sich bleibt meistens gleich wobei man für Stable Diffusion eine Liste mit Einstellungen bekommt die man vornehmen kann. Hiermit lässt man sich nun Bilder erstellen. Ist ein Bild dabei auf dessen Basis man weiterarbeiten will, kopiert man sich den Samen und fügt diese mehrstellige Nummer in das „Samen-Feld“ ein. Nun kann man das Originalbild verändern. Beispielsweise eine zweite Sonne einfügen oder Nebel.
Die Ergebnisse werden besser, um so genauer der Prompt das Bild beschreibt. Dabei leistet ChatGPT phantastische Arbeit. Hier ein Beispiel für Midjourey:
A vast, flat snow-covered plain stretching endlessly to the horizon. The snow is fresh and untouched, yet appears somewhat somber under the overcast sky. Thick clouds shimmer in soft pink and violet tones, casting a surreal glow over the landscape. In the background, the majestic Ross Ice Shelf rises, with its massive frozen structures and deep, shadowy ice caves. The caves subtly reflect the faint light, adding depth and mystery. The entire environment is still and quiet, evoking a contemplative and serene wintery scene. --ar 9:16 --v 6 --style raw --q 2
Nun haben wir unser Wunschbild, aber in einer Qualität die schon im Jahr 2000 nicht mehr „State of the Art“ war. Deshalb geht es nun zu Nero-AI. Die waren früher für was anderes bekannt. Nun bietet Nero einen ausgezeichneten AI Image Upscaler an. Bild hochladen, Upscale Rate auf x4 einstellen, warten und staunen.
An dieser Stelle möchte ich noch erwähnen, das dieser Guide auf mehrfachen Wunsch von Lesern meines Blogs entstanden ist. Das Thema AI ist momentan permanent im Wandel. Jeden Tag gibt es etwas neues. Und so ist auch bei diesem Artikel fraglich wie lange er aktuell ist. Trotzdem wünsche ich viel Spaß beim rumprobieren.